When running e2e tests on flaky networks, gravatar can cause a timeout
and test failures. Turn off, and populate avatars on e2e test suite run
to make them reliable.
In profiling integration tests, I found a couple places where per-test
overhead could be reduced:
* Avoiding disk IO by synchronizing instead of deleting & copying test
Git repository data. This saves ~100ms per test on my machine
* When flushing queues in `PrintCurrentTest`, invoke `FlushWithContext`
in a parallel.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
This PR introduces a new event which is similar as Github's. When a new
commit status submitted, the event will be trigged. That means, now we
can receive all feedback from CI/CD system in webhooks or other notify
systems.
ref:
https://docs.github.com/en/webhooks/webhook-events-and-payloads#statusFix#20749
- [x] Move `CreateRepositoryByExample` to service layer
- [x] Move `AddCollabrator` to service layer
- [x] Add a new parameter for `AddCollabrator` so that changing mode
immediately after that will become unnecessary.
Fix#31137.
Replace #31623#31697.
When migrating LFS objects, if there's any object that failed (like some
objects are losted, which is not really critical), Gitea will stop
migrating LFS immediately but treat the migration as successful.
This PR checks the error according to the [LFS api
doc](https://github.com/git-lfs/git-lfs/blob/main/docs/api/batch.md#successful-responses).
> LFS object error codes should match HTTP status codes where possible:
>
> - 404 - The object does not exist on the server.
> - 409 - The specified hash algorithm disagrees with the server's
acceptable options.
> - 410 - The object was removed by the owner.
> - 422 - Validation error.
If the error is `404`, it's safe to ignore it and continue migration.
Otherwise, stop the migration and mark it as failed to ensure data
integrity of LFS objects.
And maybe we should also ignore others errors (maybe `410`? I'm not sure
what's the difference between "does not exist" and "removed by the
owner".), we can add it later when some users report that they have
failed to migrate LFS because of an error which should be ignored.
Merging PR may fail because of various problems. The pull request may
have a dirty state because there is no transaction when merging a pull
request. ref
https://github.com/go-gitea/gitea/pull/25741#issuecomment-2074126393
This PR moves all database update operations to post-receive handler for
merging a pull request and having a database transaction. That means if
database operations fail, then the git merging will fail, the git client
will get a fail result.
There are already many tests for pull request merging, so we don't need
to add a new one.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Noteable additions:
- `redefines-builtin-id` forbid variable names that shadow go builtins
- `empty-lines` remove unnecessary empty lines that `gofumpt` does not
remove for some reason
- `superfluous-else` eliminate more superfluous `else` branches
Rules are also sorted alphabetically and I cleaned up various parts of
`.golangci.yml`.
Part of #23318
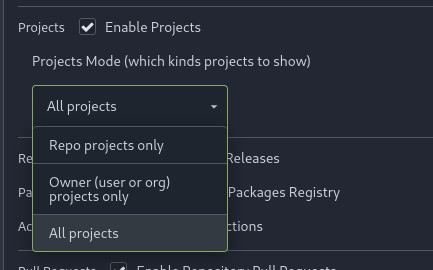
Add menu in repo settings to allow for repo admin to decide not just if
projects are enabled or disabled per repo, but also which kind of
projects (repo-level/owner-level) are enabled. If repo projects
disabled, don't show the projects tab.
---------
Co-authored-by: delvh <dev.lh@web.de>
Fix#28843
This PR will bypass the pushUpdateTag to database failure when
syncAllTags. An error log will be recorded.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
With this option, it is possible to require a linear commit history with
the following benefits over the next best option `Rebase+fast-forward`:
The original commits continue existing, with the original signatures
continuing to stay valid instead of being rewritten, there is no merge
commit, and reverting commits becomes easier.
Closes#24906
## Purpose
This is a refactor toward building an abstraction over managing git
repositories.
Afterwards, it does not matter anymore if they are stored on the local
disk or somewhere remote.
## What this PR changes
We used `git.OpenRepository` everywhere previously.
Now, we should split them into two distinct functions:
Firstly, there are temporary repositories which do not change:
```go
git.OpenRepository(ctx, diskPath)
```
Gitea managed repositories having a record in the database in the
`repository` table are moved into the new package `gitrepo`:
```go
gitrepo.OpenRepository(ctx, repo_model.Repo)
```
Why is `repo_model.Repository` the second parameter instead of file
path?
Because then we can easily adapt our repository storage strategy.
The repositories can be stored locally, however, they could just as well
be stored on a remote server.
## Further changes in other PRs
- A Git Command wrapper on package `gitrepo` could be created. i.e.
`NewCommand(ctx, repo_model.Repository, commands...)`. `git.RunOpts{Dir:
repo.RepoPath()}`, the directory should be empty before invoking this
method and it can be filled in the function only. #28940
- Remove the `RepoPath()`/`WikiPath()` functions to reduce the
possibility of mistakes.
---------
Co-authored-by: delvh <dev.lh@web.de>
Fix#22066
# Purpose
This PR fix the releases will be deleted when mirror repository sync the
tags.
# The problem
In the previous implementation of #19125. All releases record in
databases of one mirror repository will be deleted before sync.
Ref:
https://github.com/go-gitea/gitea/pull/19125/files#diff-2aa04998a791c30e5a02b49a97c07fcd93d50e8b31640ce2ddb1afeebf605d02R481
# The Pros
This PR introduced a new method which will load all releases from
databases and all tags on git data into memory. And detect which tags
needs to be inserted, which tags need to be updated or deleted. Only
tags releases(IsTag=true) which are not included in git data will be
deleted, only tags which sha1 changed will be updated. So it will not
delete any real releases include drafts.
# The Cons
The drawback is the memory usage will be higher than before if there are
many tags on this repository. This PR defined a special release struct
to reduce columns loaded from database to memory.
The 4 functions are duplicated, especially as interface methods. I think
we just need to keep `MustID` the only one and remove other 3.
```
MustID(b []byte) ObjectID
MustIDFromString(s string) ObjectID
NewID(b []byte) (ObjectID, error)
NewIDFromString(s string) (ObjectID, error)
```
Introduced the new interfrace method `ComputeHash` which will replace
the interface `HasherInterface`. Now we don't need to keep two
interfaces.
Reintroduced `git.NewIDFromString` and `git.MustIDFromString`. The new
function will detect the hash length to decide which objectformat of it.
If it's 40, then it's SHA1. If it's 64, then it's SHA256. This will be
right if the commitID is a full one. So the parameter should be always a
full commit id.
@AdamMajer Please review.
- Remove `ObjectFormatID`
- Remove function `ObjectFormatFromID`.
- Use `Sha1ObjectFormat` directly but not a pointer because it's an
empty struct.
- Store `ObjectFormatName` in `repository` struct
Refactor Hash interfaces and centralize hash function. This will allow
easier introduction of different hash function later on.
This forms the "no-op" part of the SHA256 enablement patch.
The function `GetByBean` has an obvious defect that when the fields are
empty values, it will be ignored. Then users will get a wrong result
which is possibly used to make a security problem.
To avoid the possibility, this PR removed function `GetByBean` and all
references.
And some new generic functions have been introduced to be used.
The recommand usage like below.
```go
// if query an object according id
obj, err := db.GetByID[Object](ctx, id)
// query with other conditions
obj, err := db.Get[Object](ctx, builder.Eq{"a": a, "b":b})
```
The git command may operate the git directory (add/remove) files in any
time.
So when the code iterates the directory, some files may disappear during
the "walk". All "IsNotExist" errors should be ignored.
Fix#26765
This PR reduces the complexity of the system setting system.
It only needs one line to introduce a new option, and the option can be
used anywhere out-of-box.
It is still high-performant (and more performant) because the config
values are cached in the config system.
This PR removed `unittest.MainTest` the second parameter
`TestOptions.GiteaRoot`. Now it detects the root directory by current
working directory.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
This PR adds a new field `RemoteAddress` to both mirror types which
contains the sanitized remote address for easier (database) access to
that information. Will be used in the audit PR if merged.
Part of #27065
This reduces the usage of `db.DefaultContext`. I think I've got enough
files for the first PR. When this is merged, I will continue working on
this.
Considering how many files this PR affect, I hope it won't take to long
to merge, so I don't end up in the merge conflict hell.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Unfortunately, when a system setting hasn't been stored in the database,
it cannot be cached.
Meanwhile, this PR also uses context cache for push email avatar display
which should avoid to read user table via email address again and again.
According to my local test, this should reduce dashboard elapsed time
from 150ms -> 80ms .
Fix#24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
When branch's commit CommitMessage is too long, the column maybe too
short.(TEXT 16K for mysql).
This PR will fix it to only store the summary because these message will
only show on branch list or possible future search?