Continuation of https://github.com/go-gitea/gitea/pull/25439. Fixes#847
Before:
<img width="1296" alt="image"
src="https://github.com/go-gitea/gitea/assets/32161460/24571ac8-b254-43c9-b178-97340f0dc8a9">
----
After:
<img width="1296" alt="image"
src="https://github.com/go-gitea/gitea/assets/32161460/c60b2459-9d10-4d42-8d83-d5ef0f45bf94">
---
#### Overview
This is the implementation of a requested feature: Contributors graph
(#847)
It makes Activity page a multi-tab page and adds a new tab called
Contributors. Contributors tab shows the contribution graphs over time
since the repository existed. It also shows per user contribution graphs
for top 100 contributors. Top 100 is calculated based on the selected
contribution type (commits, additions or deletions).
---
#### Demo
(The demo is a bit old but still a good example to show off the main
features)
<video src="https://github.com/go-gitea/gitea/assets/32161460/9f68103f-8145-4cc2-94bc-5546daae7014" controls width="320" height="240">
<a href="https://github.com/go-gitea/gitea/assets/32161460/9f68103f-8145-4cc2-94bc-5546daae7014">Download</a>
</video>
#### Features:
- Select contribution type (commits, additions or deletions)
- See overall and per user contribution graphs for the selected
contribution type
- Zoom and pan on graphs to see them in detail
- See top 100 contributors based on the selected contribution type and
selected time range
- Go directly to users' profile by clicking their name if they are
registered gitea users
- Cache the results so that when the same repository is visited again
fetching data will be faster
---------
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: hiifong <i@hiif.ong>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: yp05327 <576951401@qq.com>
In #28691, schedule plans will be deleted when a repo's actions unit is
disabled. But when the unit is enabled, the schedule plans won't be
created again.
This PR fixes the bug. The schedule plans will be created again when the
actions unit is re-enabled
## Purpose
This is a refactor toward building an abstraction over managing git
repositories.
Afterwards, it does not matter anymore if they are stored on the local
disk or somewhere remote.
## What this PR changes
We used `git.OpenRepository` everywhere previously.
Now, we should split them into two distinct functions:
Firstly, there are temporary repositories which do not change:
```go
git.OpenRepository(ctx, diskPath)
```
Gitea managed repositories having a record in the database in the
`repository` table are moved into the new package `gitrepo`:
```go
gitrepo.OpenRepository(ctx, repo_model.Repo)
```
Why is `repo_model.Repository` the second parameter instead of file
path?
Because then we can easily adapt our repository storage strategy.
The repositories can be stored locally, however, they could just as well
be stored on a remote server.
## Further changes in other PRs
- A Git Command wrapper on package `gitrepo` could be created. i.e.
`NewCommand(ctx, repo_model.Repository, commands...)`. `git.RunOpts{Dir:
repo.RepoPath()}`, the directory should be empty before invoking this
method and it can be filled in the function only. #28940
- Remove the `RepoPath()`/`WikiPath()` functions to reduce the
possibility of mistakes.
---------
Co-authored-by: delvh <dev.lh@web.de>
The method can't be called with an outer transaction because if the user
is not a collaborator the outer transaction will be rolled back even if
the inner transaction uses the no-error path.
`has == 0` leads to `return nil` which cancels the transaction. A
standalone call of this method does nothing but if used with an outer
transaction, that will be canceled.
Fixes#22236
---
Error occurring currently while trying to revert commit using read-tree
-m approach:
> 2022/12/26 16:04:43 ...rvices/pull/patch.go:240:AttemptThreeWayMerge()
[E] [63a9c61a] Unable to run read-tree -m! Error: exit status 128 -
fatal: this operation must be run in a work tree
> - fatal: this operation must be run in a work tree
We need to clone a non-bare repository for `git read-tree -m` to work.
bb371aee6e
adds support to create a non-bare cloned temporary upload repository.
After cloning a non-bare temporary upload repository, we [set default
index](https://github.com/go-gitea/gitea/blob/main/services/repository/files/cherry_pick.go#L37)
(`git read-tree HEAD`).
This operation ends up resetting the git index file (see investigation
details below), due to which, we need to call `git update-index
--refresh` afterward.
Here's the diff of the index file before and after we execute
SetDefaultIndex: https://www.diffchecker.com/hyOP3eJy/
Notice the **ctime**, **mtime** are set to 0 after SetDefaultIndex.
You can reproduce the same behavior using these steps:
```bash
$ git clone https://try.gitea.io/me-heer/test.git -s -b main
$ cd test
$ git read-tree HEAD
$ git read-tree -m 1f085d7ed8 1f085d7ed8 9933caed00
error: Entry '1' not uptodate. Cannot merge.
```
After which, we can fix like this:
```
$ git update-index --refresh
$ git read-tree -m 1f085d7ed8 1f085d7ed8 9933caed00
```
Fix#28157
This PR fix the possible bugs about actions schedule.
## The Changes
- Move `UpdateRepositoryUnit` and `SetRepoDefaultBranch` from models to
service layer
- Remove schedules plan from database and cancel waiting & running
schedules tasks in this repository when actions unit has been disabled
or global disabled.
- Remove schedules plan from database and cancel waiting & running
schedules tasks in this repository when default branch changed.
#28361 introduced `syncBranchToDB` in `CreateNewBranchFromCommit`. This
PR will revert the change because it's unnecessary. Every push will
already be checked by `syncBranchToDB`.
This PR also created a test to ensure it's right.
Introduce the new generic deletion methods
- `func DeleteByID[T any](ctx context.Context, id int64) (int64, error)`
- `func DeleteByIDs[T any](ctx context.Context, ids ...int64) error`
- `func Delete[T any](ctx context.Context, opts FindOptions) (int64,
error)`
So, we no longer need any specific deletion method and can just use
the generic ones instead.
Replacement of #28450Closes#28450
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Nowadays, cache will be used on almost everywhere of Gitea and it cannot
be disabled, otherwise some features will become unaviable.
Then I think we can just remove the option for cache enable. That means
cache cannot be disabled.
But of course, we can still use cache configuration to set how should
Gitea use the cache.
- Remove `ObjectFormatID`
- Remove function `ObjectFormatFromID`.
- Use `Sha1ObjectFormat` directly but not a pointer because it's an
empty struct.
- Store `ObjectFormatName` in `repository` struct
Refactor Hash interfaces and centralize hash function. This will allow
easier introduction of different hash function later on.
This forms the "no-op" part of the SHA256 enablement patch.
Fix#28056
This PR will check whether the repo has zero branch when pushing a
branch. If that, it means this repository hasn't been synced.
The reason caused that is after user upgrade from v1.20 -> v1.21, he
just push branches without visit the repository user interface. Because
all repositories routers will check whether a branches sync is necessary
but push has not such check.
For every repository, it has two states, synced or not synced. If there
is zero branch for a repository, then it will be assumed as non-sync
state. Otherwise, it's synced state. So if we think it's synced, we just
need to update branch/insert new branch. Otherwise do a full sync. So
that, for every push, there will be almost no extra load added. It's
high performance than yours.
For the implementation, we in fact will try to update the branch first,
if updated success with affect records > 0, then all are done. Because
that means the branch has been in the database. If no record is
affected, that means the branch does not exist in database. So there are
two possibilities. One is this is a new branch, then we just need to
insert the record. Another is the branches haven't been synced, then we
need to sync all the branches into database.
The function `GetByBean` has an obvious defect that when the fields are
empty values, it will be ignored. Then users will get a wrong result
which is possibly used to make a security problem.
To avoid the possibility, this PR removed function `GetByBean` and all
references.
And some new generic functions have been introduced to be used.
The recommand usage like below.
```go
// if query an object according id
obj, err := db.GetByID[Object](ctx, id)
// query with other conditions
obj, err := db.Get[Object](ctx, builder.Eq{"a": a, "b":b})
```
- Push commits updates are run in a queue and updates can come from less
traceable places such as Git over SSH, therefor add more information
about on which repository the pushUpdate failed.
Refs: https://codeberg.org/forgejo/forgejo/pulls/1723
(cherry picked from commit 37ab9460394800678d2208fed718e719d7a5d96f)
Co-authored-by: Gusted <postmaster@gusted.xyz>
This PR removed `unittest.MainTest` the second parameter
`TestOptions.GiteaRoot`. Now it detects the root directory by current
working directory.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
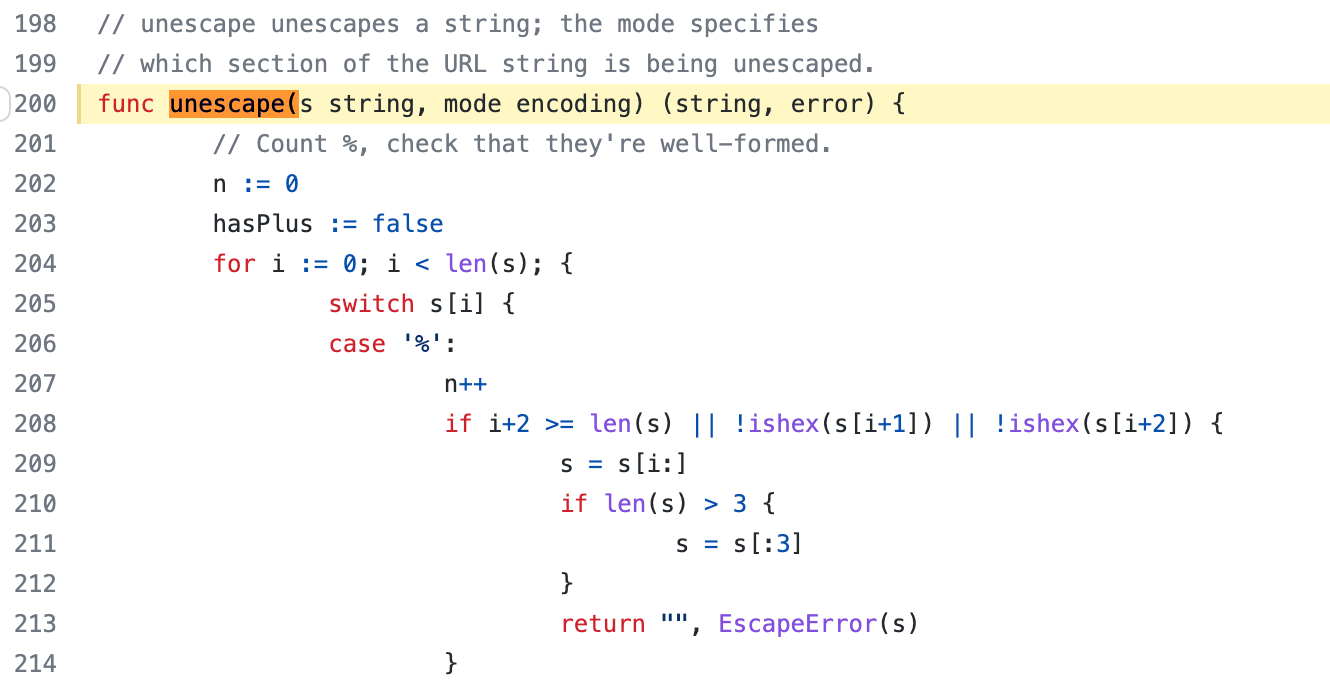
Part of #27065
This reduces the usage of `db.DefaultContext`. I think I've got enough
files for the first PR. When this is merged, I will continue working on
this.
Considering how many files this PR affect, I hope it won't take to long
to merge, so I don't end up in the merge conflict hell.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Just like `models/unittest`, the testing helper functions should be in a
separate package: `contexttest`
And complete the TODO:
> // TODO: move this function to other packages, because it depends on
"models" package
This PR
- Fix#26093. Replace `time.Time` with `timeutil.TimeStamp`
- Fix#26135. Add missing `xorm:"extends"` to `CountLFSMetaObject` for
LFS meta object query
- Add a unit test for LFS meta object garbage collection
To avoid deadlock problem, almost database related functions should be
have ctx as the first parameter.
This PR do a refactor for some of these functions.
Before: the concept "Content string" is used everywhere. It has some
problems:
1. Sometimes it means "base64 encoded content", sometimes it means "raw
binary content"
2. It doesn't work with large files, eg: uploading a 1G LFS file would
make Gitea process OOM
This PR does the refactoring: use "ContentReader" / "ContentBase64"
instead of "Content"
This PR is not breaking because the key in API JSON is still "content":
`` ContentBase64 string `json:"content"` ``
Related issue: #18368
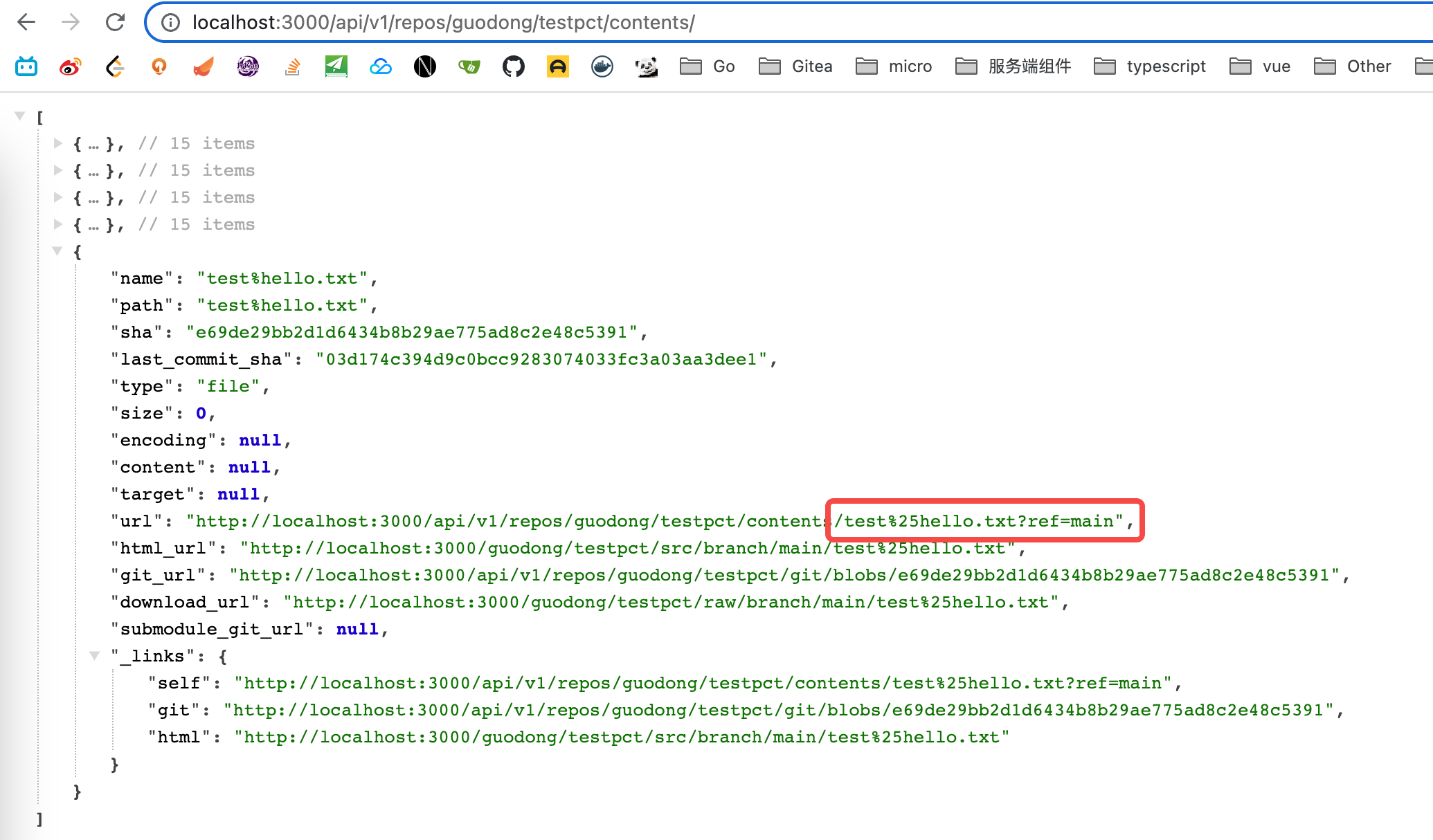
It doesn't seem right to "guess" the file encoding/BOM when using API to
upload files.
The API should save the uploaded content as-is.
Remove unnecessary `if opts.Logger != nil` checks.
* For "CLI doctor" mode, output to the console's "logger.Info".
* For "Web Task" mode, output to the default "logger.Debug", to avoid
flooding the server's log in a busy production instance.
Co-authored-by: Giteabot <teabot@gitea.io>
When branch's commit CommitMessage is too long, the column maybe too
short.(TEXT 16K for mysql).
This PR will fix it to only store the summary because these message will
only show on branch list or possible future search?
Related #14180
Related #25233
Related #22639Close#19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
1. The "web" package shouldn't depends on "modules/context" package,
instead, let each "web context" register themselves to the "web"
package.
2. The old Init/Free doesn't make sense, so simplify it
* The ctx in "Init(ctx)" is never used, and shouldn't be used that way
* The "Free" is never called and shouldn't be called because the SSPI
instance is shared
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Extract from #22743
`DeleteBranch` will trigger a push update event, so that
`pull_service.CloseBranchPulls` has been invoked twice and
`AddDeletedBranch` is better to be moved to push update then even user
delete a branch via git command, it will also be triggered.
Co-authored-by: Giteabot <teabot@gitea.io>
This PR creates an API endpoint for creating/updating/deleting multiple
files in one API call similar to the solution provided by
[GitLab](https://docs.gitlab.com/ee/api/commits.html#create-a-commit-with-multiple-files-and-actions).
To archive this, the CreateOrUpdateRepoFile and DeleteRepoFIle functions
in files service are unified into one function supporting multiple files
and actions.
Resolves#14619
Before there was a "graceful function": RunWithShutdownFns, it's mainly
for some modules which doesn't support context.
The old queue system doesn't work well with context, so the old queues
need it.
After the queue refactoring, the new queue works with context well, so,
use Golang context as much as possible, the `RunWithShutdownFns` could
be removed (replaced by RunWithCancel for context cancel mechanism), the
related code could be simplified.
This PR also fixes some legacy queue-init problems, eg:
* typo : archiver: "unable to create codes indexer queue" => "unable to
create repo-archive queue"
* no nil check for failed queues, which causes unfriendly panic
After this PR, many goroutines could have better display name:


This PR replaces all string refName as a type `git.RefName` to make the
code more maintainable.
Fix#15367
Replaces #23070
It also fixed a bug that tags are not sync because `git remote --prune
origin` will not remove local tags if remote removed.
We in fact should use `git fetch --prune --tags origin` but not `git
remote update origin` to do the sync.
Some answer from ChatGPT as ref.
> If the git fetch --prune --tags command is not working as expected,
there could be a few reasons why. Here are a few things to check:
>
>Make sure that you have the latest version of Git installed on your
system. You can check the version by running git --version in your
terminal. If you have an outdated version, try updating Git and see if
that resolves the issue.
>
>Check that your Git repository is properly configured to track the
remote repository's tags. You can check this by running git config
--get-all remote.origin.fetch and verifying that it includes
+refs/tags/*:refs/tags/*. If it does not, you can add it by running git
config --add remote.origin.fetch "+refs/tags/*:refs/tags/*".
>
>Verify that the tags you are trying to prune actually exist on the
remote repository. You can do this by running git ls-remote --tags
origin to list all the tags on the remote repository.
>
>Check if any local tags have been created that match the names of tags
on the remote repository. If so, these local tags may be preventing the
git fetch --prune --tags command from working properly. You can delete
local tags using the git tag -d command.
---------
Co-authored-by: delvh <dev.lh@web.de>
# ⚠️ Breaking
Many deprecated queue config options are removed (actually, they should
have been removed in 1.18/1.19).
If you see the fatal message when starting Gitea: "Please update your
app.ini to remove deprecated config options", please follow the error
messages to remove these options from your app.ini.
Example:
```
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].ISSUE_INDEXER_QUEUE_TYPE`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].UPDATE_BUFFER_LEN`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [F] Please update your app.ini to remove deprecated config options
```
Many options in `[queue]` are are dropped, including:
`WRAP_IF_NECESSARY`, `MAX_ATTEMPTS`, `TIMEOUT`, `WORKERS`,
`BLOCK_TIMEOUT`, `BOOST_TIMEOUT`, `BOOST_WORKERS`, they can be removed
from app.ini.
# The problem
The old queue package has some legacy problems:
* complexity: I doubt few people could tell how it works.
* maintainability: Too many channels and mutex/cond are mixed together,
too many different structs/interfaces depends each other.
* stability: due to the complexity & maintainability, sometimes there
are strange bugs and difficult to debug, and some code doesn't have test
(indeed some code is difficult to test because a lot of things are mixed
together).
* general applicability: although it is called "queue", its behavior is
not a well-known queue.
* scalability: it doesn't seem easy to make it work with a cluster
without breaking its behaviors.
It came from some very old code to "avoid breaking", however, its
technical debt is too heavy now. It's a good time to introduce a better
"queue" package.
# The new queue package
It keeps using old config and concept as much as possible.
* It only contains two major kinds of concepts:
* The "base queue": channel, levelqueue, redis
* They have the same abstraction, the same interface, and they are
tested by the same testing code.
* The "WokerPoolQueue", it uses the "base queue" to provide "worker
pool" function, calls the "handler" to process the data in the base
queue.
* The new code doesn't do "PushBack"
* Think about a queue with many workers, the "PushBack" can't guarantee
the order for re-queued unhandled items, so in new code it just does
"normal push"
* The new code doesn't do "pause/resume"
* The "pause/resume" was designed to handle some handler's failure: eg:
document indexer (elasticsearch) is down
* If a queue is paused for long time, either the producers blocks or the
new items are dropped.
* The new code doesn't do such "pause/resume" trick, it's not a common
queue's behavior and it doesn't help much.
* If there are unhandled items, the "push" function just blocks for a
few seconds and then re-queue them and retry.
* The new code doesn't do "worker booster"
* Gitea's queue's handlers are light functions, the cost is only the
go-routine, so it doesn't make sense to "boost" them.
* The new code only use "max worker number" to limit the concurrent
workers.
* The new "Push" never blocks forever
* Instead of creating more and more blocking goroutines, return an error
is more friendly to the server and to the end user.
There are more details in code comments: eg: the "Flush" problem, the
strange "code.index" hanging problem, the "immediate" queue problem.
Almost ready for review.
TODO:
* [x] add some necessary comments during review
* [x] add some more tests if necessary
* [x] update documents and config options
* [x] test max worker / active worker
* [x] re-run the CI tasks to see whether any test is flaky
* [x] improve the `handleOldLengthConfiguration` to provide more
friendly messages
* [x] fine tune default config values (eg: length?)
## Code coverage:

There was only one `IsRepositoryExist` function, it did: `has && isDir`
However it's not right, and it would cause 500 error when creating a new
repository if the dir exists.
Then, it was changed to `has || isDir`, it is still incorrect, it
affects the "adopt repo" logic.
To make the logic clear:
* IsRepositoryModelOrDirExist
* IsRepositoryModelExist
Since #23493 has conflicts with latest commits, this PR is my proposal
for fixing #23371
Details are in the comments
And refactor the `modules/options` module, to make it always use
"filepath" to access local files.
Benefits:
* No need to do `util.CleanPath(strings.ReplaceAll(p, "\\", "/"))),
"/")` any more (not only one before)
* The function behaviors are clearly defined
When the base repository contains multiple branches with the same
commits as the base branch, pull requests can show a long list of
commits already in the base branch as having been added.
What this is supposed to do is exclude commits already in the base
branch. But the mechansim to do so assumed a commit only exists in a
single branch. Now use `git rev-list A B --not branchName` instead of
filtering commits afterwards.
The logic to detect if there was a force push also was wrong for
multiple branches. If the old commit existed in any branch in the base
repository it would assume there was no force push. Instead check if the
old commit is an ancestor of the new commit.
Related to: #22294#23186#23054
Replace: #23218
Some discussion is in the comments of #23218.
Highlights:
- Add Expiration for cache context. If a cache context has been used for
more than 10s, the cache data will be ignored, and warning logs will be
printed.
- Add `discard` field to `cacheContext`, a `cacheContext` with `discard`
true will drop all cached data and won't store any new one.
- Introduce `WithNoCacheContext`, if one wants to run long-life tasks,
but the parent context is a cache context,
`WithNoCacheContext(perentCtx)` will discard the cache data, so it will
be safe to keep the context for a long time.
- It will be fine to treat an original context as a cache context, like
`GetContextData(context.Backgraud())`, no warning logs will be printed.
Some cases about nesting:
When:
- *A*, *B* or *C* means a cache context.
- ~*A*~, ~*B*~ or ~*C*~ means a discard cache context.
- `ctx` means `context.Backgrand()`
- *A(ctx)* means a cache context with `ctx` as the parent context.
- *B(A(ctx))* means a cache context with `A(ctx)` as the parent context.
- `With` means `WithCacheContext`
- `WithNo` means `WithNoCacheContext`
So:
- `With(ctx)` -> *A(ctx)*
- `With(With(ctx))` -> *A(ctx)*, not *B(A(ctx))*
- `With(With(With(ctx)))` -> *A(ctx)*, not *C(B(A(ctx)))*
- `WithNo(ctx)` -> *ctx*, not *~A~(ctx)*
- `WithNo(With(ctx))` -> *~A~(ctx)*
- `WithNo(WithNo(With(ctx)))` -> *~A~(ctx)*, not *~B~(~A~(ctx))*
- `With(WithNo(With(ctx)))` -> *B(~A~(ctx))*
- `WithNo(With(WithNo(With(ctx))))` -> *~B~(~A~(ctx))*
- `With(WithNo(With(WithNo(With(ctx)))))` -> *C(~B~(~A~(ctx)))*
Add a new "exclusive" option per label. This makes it so that when the
label is named `scope/name`, no other label with the same `scope/`
prefix can be set on an issue.
The scope is determined by the last occurence of `/`, so for example
`scope/alpha/name` and `scope/beta/name` are considered to be in
different scopes and can coexist.
Exclusive scopes are not enforced by any database rules, however they
are enforced when editing labels at the models level, automatically
removing any existing labels in the same scope when either attaching a
new label or replacing all labels.
In menus use a circle instead of checkbox to indicate they function as
radio buttons per scope. Issue filtering by label ensures that only a
single scoped label is selected at a time. Clicking with alt key can be
used to remove a scoped label, both when editing individual issues and
batch editing.
Label rendering refactor for consistency and code simplification:
* Labels now consistently have the same shape, emojis and tooltips
everywhere. This includes the label list and label assignment menus.
* In label list, show description below label same as label menus.
* Don't use exactly black/white text colors to look a bit nicer.
* Simplify text color computation. There is no point computing luminance
in linear color space, as this is a perceptual problem and sRGB is
closer to perceptually linear.
* Increase height of label assignment menus to show more labels. Showing
only 3-4 labels at a time leads to a lot of scrolling.
* Render all labels with a new RenderLabel template helper function.
Label creation and editing in multiline modal menu:
* Change label creation to open a modal menu like label editing.
* Change menu layout to place name, description and colors on separate
lines.
* Don't color cancel button red in label editing modal menu.
* Align text to the left in model menu for better readability and
consistent with settings layout elsewhere.
Custom exclusive scoped label rendering:
* Display scoped label prefix and suffix with slightly darker and
lighter background color respectively, and a slanted edge between them
similar to the `/` symbol.
* In menus exclusive labels are grouped with a divider line.
---------
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
Most of the time forks are used for contributing code only, so not
having
issues, projects, release and packages is a better default for such
cases.
They can still be enabled in the settings.
A new option `DEFAULT_FORK_REPO_UNITS` is added to configure the default
units on forks.
Also add missing `repo.packages` unit to documentation.
code by: @brechtvl
## ⚠️ BREAKING ⚠️
When forking a repository, the fork will now have issues, projects,
releases, packages and wiki disabled. These can be enabled in the
repository settings afterwards. To change back to the previous default
behavior, configure `DEFAULT_FORK_REPO_UNITS` to be the same value as
`DEFAULT_REPO_UNITS`.
Co-authored-by: Brecht Van Lommel <brecht@blender.org>
This PR follows #21535 (and replace #22592)
## Review without space diff
https://github.com/go-gitea/gitea/pull/22678/files?diff=split&w=1
## Purpose of this PR
1. Make git module command completely safe (risky user inputs won't be
passed as argument option anymore)
2. Avoid low-level mistakes like
https://github.com/go-gitea/gitea/pull/22098#discussion_r1045234918
3. Remove deprecated and dirty `CmdArgCheck` function, hide the `CmdArg`
type
4. Simplify code when using git command
## The main idea of this PR
* Move the `git.CmdArg` to the `internal` package, then no other package
except `git` could use it. Then developers could never do
`AddArguments(git.CmdArg(userInput))` any more.
* Introduce `git.ToTrustedCmdArgs`, it's for user-provided and already
trusted arguments. It's only used in a few cases, for example: use git
arguments from config file, help unit test with some arguments.
* Introduce `AddOptionValues` and `AddOptionFormat`, they make code more
clear and simple:
* Before: `AddArguments("-m").AddDynamicArguments(message)`
* After: `AddOptionValues("-m", message)`
* -
* Before: `AddArguments(git.CmdArg(fmt.Sprintf("--author='%s <%s>'",
sig.Name, sig.Email)))`
* After: `AddOptionFormat("--author='%s <%s>'", sig.Name, sig.Email)`
## FAQ
### Why these changes were not done in #21535 ?
#21535 is mainly a search&replace, it did its best to not change too
much logic.
Making the framework better needs a lot of changes, so this separate PR
is needed as the second step.
### The naming of `AddOptionXxx`
According to git's manual, the `--xxx` part is called `option`.
### How can it guarantee that `internal.CmdArg` won't be not misused?
Go's specification guarantees that. Trying to access other package's
internal package causes compilation error.
And, `golangci-lint` also denies the git/internal package. Only the
`git/command.go` can use it carefully.
### There is still a `ToTrustedCmdArgs`, will it still allow developers
to make mistakes and pass untrusted arguments?
Generally speaking, no. Because when using `ToTrustedCmdArgs`, the code
will be very complex (see the changes for examples). Then developers and
reviewers can know that something might be unreasonable.
### Why there was a `CmdArgCheck` and why it's removed?
At the moment of #21535, to reduce unnecessary changes, `CmdArgCheck`
was introduced as a hacky patch. Now, almost all code could be written
as `cmd := NewCommand(); cmd.AddXxx(...)`, then there is no need for
`CmdArgCheck` anymore.
### Why many codes for `signArg == ""` is deleted?
Because in the old code, `signArg` could never be empty string, it's
either `-S[key-id]` or `--no-gpg-sign`. So the `signArg == ""` is just
dead code.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
The update by rebase code reuses the merge code but shortcircuits and
pushes back up to the head. However, it doesn't set the correct pushing
environment - and just uses the same environment as the base repo. This
leads to the push update failing and thence the PR becomes out-of-sync
with the head.
This PR fixes this and adjusts the trace logging elsewhere to help make
this clearer.
Fix#18802
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
This PR adds a task to the cron service to allow garbage collection of
LFS meta objects. As repositories may have a large number of
LFSMetaObjects, an updated column is added to this table and it is used
to perform a generational GC to attempt to reduce the amount of work.
(There may need to be a bit more work here but this is probably enough
for the moment.)
Fix#7045
Signed-off-by: Andrew Thornton <art27@cantab.net>
As suggest by Go developers, use `filepath.WalkDir` instead of
`filepath.Walk` because [*Walk is less efficient than WalkDir,
introduced in Go 1.16, which avoids calling `os.Lstat` on every file or
directory visited](https://pkg.go.dev/path/filepath#Walk).
This proposition address that, in a similar way as
https://github.com/go-gitea/gitea/pull/22392 did.
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This PR introduce glob match for protected branch name. The separator is
`/` and you can use `*` matching non-separator chars and use `**` across
separator.
It also supports input an exist or non-exist branch name as matching
condition and branch name condition has high priority than glob rule.
Should fix#2529 and #15705
screenshots
<img width="1160" alt="image"
src="https://user-images.githubusercontent.com/81045/205651179-ebb5492a-4ade-4bb4-a13c-965e8c927063.png">
Co-authored-by: zeripath <art27@cantab.net>
The current code propagates all errors up to the iteration step meaning
that a single malformed repo will prevent GC of other repos.
This PR simply stops that propagation.
Fix#21605
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
We can use `:=` to make `err` local to the if-scope instead of
overwriting the `err` in outer scope.
Signed-off-by: jolheiser <john.olheiser@gmail.com>
After #22362, we can feel free to use transactions without
`db.DefaultContext`.
And there are still lots of models using `db.DefaultContext`, I think we
should refactor them carefully and one by one.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}