After #22362, we can feel free to use transactions without
`db.DefaultContext`.
And there are still lots of models using `db.DefaultContext`, I think we
should refactor them carefully and one by one.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
- Unify the hashing code for repository and user avatars into a
function.
- Use a sane hash function instead of MD5.
- Only require hashing once instead of twice(w.r.t. hashing for user
avatar).
- Improve the comment for the hashing code of why it works.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Previously, there was an `import services/webhooks` inside
`modules/notification/webhook`.
This import was removed (after fighting against many import cycles).
Additionally, `modules/notification/webhook` was moved to
`modules/webhook`,
and a few structs/constants were extracted from `models/webhooks` to
`modules/webhook`.
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This PR changed the Auth interface signature from
`Verify(http *http.Request, w http.ResponseWriter, store DataStore, sess
SessionStore) *user_model.User`
to
`Verify(http *http.Request, w http.ResponseWriter, store DataStore, sess
SessionStore) (*user_model.User, error)`.
There is a new return argument `error` which means the verification
condition matched but verify process failed, we should stop the auth
process.
Before this PR, when return a `nil` user, we don't know the reason why
it returned `nil`. If the match condition is not satisfied or it
verified failure? For these two different results, we should have
different handler. If the match condition is not satisfied, we should
try next auth method and if there is no more auth method, it's an
anonymous user. If the condition matched but verify failed, the auth
process should be stop and return immediately.
This will fix#20563
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Co-authored-by: Jason Song <i@wolfogre.com>
If user has reached the maximum limit of repositories:
- Before
- disallow create
- allow fork without limit
- This patch:
- disallow create
- disallow fork
- Add option `ALLOW_FORK_WITHOUT_MAXIMUM_LIMIT` (Default **true**) :
enable this allow user fork repositories without maximum number limit
fixed https://github.com/go-gitea/gitea/issues/21847
Signed-off-by: Xinyu Zhou <i@sourcehut.net>
Some dbs require that all tables have primary keys, see
- #16802
- #21086
We can add a test to keep it from being broken again.
Edit:
~Added missing primary key for `ForeignReference`~ Dropped the
`ForeignReference` table to satisfy the check, so it closes#21086.
More context can be found in comments.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: zeripath <art27@cantab.net>
For a long time Gitea has tested PR patches using a git apply --check
method, and in fact prior to the introduction of a read-tree assisted
three-way merge in #18004, this was the only way of checking patches.
Since #18004, the git apply --check method has been a fallback method,
only used when the read-tree three-way merge method has detected a
conflict. The read-tree assisted three-way merge method is much faster
and less resource intensive method of detecting conflicts. #18004 kept
the git apply method around because it was thought possible that this
fallback might be able to rectify conflicts that the read-tree three-way
merge detected. I am not certain if this could ever be the case.
Given the uncertainty here and the now relative stability of the
read-tree method - this PR makes using this fallback optional and
disables it by default. The hope is that users will not notice any
significant difference in conflict detection and we will be able to
remove the git apply fallback in future, and/or improve the read-tree
three-way merge method to catch any conflicts that git apply method
might have been able to fix.
An additional benefit is that patch checking should be significantly
less resource intensive and much quicker.
(See
https://github.com/go-gitea/gitea/issues/22083\#issuecomment-1347961737)
Ref #22083
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
This fixes a bug where, when searching unadopted repositories, active
repositories will be listed as well. This is because the size of the
array of repository names to check is larger by one than the
`IterateBufferSize`.
For an `IterateBufferSize` of 50, the original code will pass 51
repository names but set the query to `LIMIT 50`. If all repositories in
the query are active (i.e. not unadopted) one of them will be omitted
from the result. Due to the `ORDER BY` clause it will be the oldest (or
least recently modified) one.
Bug found in 1.17.3.
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
The recent PR adding orphaned checks to the LFS storage is not
sufficient to completely GC LFS, as it is possible for LFSMetaObjects to
remain associated with repos but still need to be garbage collected.
Imagine a situation where a branch is uploaded containing LFS files but
that branch is later completely deleted. The LFSMetaObjects will remain
associated with the Repository but the Repository will no longer contain
any pointers to the object.
This PR adds a second doctor command to perform a full GC.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Moved files in a patch will result in git apply returning:
```
error: {filename}: No such file or directory
```
This wasn't handled by the git apply patch code. This PR adds handling
for this.
Fix#22083
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Close#14601Fix#3690
Revive of #14601.
Updated to current code, cleanup and added more read/write checks.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andre Bruch <ab@andrebruch.com>
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Norwin <git@nroo.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
When deleting a closed issue, we should update both `NumIssues`and
`NumClosedIssues`, or `NumOpenIssues`(`= NumIssues -NumClosedIssues`)
will be wrong. It's the same for pull requests.
Releated to #21557.
Alse fixed two harmless problems:
- The SQL to check issue/PR total numbers is wrong, that means it will
update the numbers even if they are correct.
- Replace legacy `num_issues = num_issues + 1` operations with
`UpdateRepoIssueNumbers`.
`hex.EncodeToString` has better performance than `fmt.Sprintf("%x",
[]byte)`, we should use it as much as possible.
I'm not an extreme fan of performance, so I think there are some
exceptions:
- `fmt.Sprintf("%x", func(...)[N]byte())`
- We can't slice the function return value directly, and it's not worth
adding lines.
```diff
func A()[20]byte { ... }
- a := fmt.Sprintf("%x", A())
- a := hex.EncodeToString(A()[:]) // invalid
+ tmp := A()
+ a := hex.EncodeToString(tmp[:])
```
- `fmt.Sprintf("%X", []byte)`
- `strings.ToUpper(hex.EncodeToString(bytes))` has even worse
performance.
Change all license headers to comply with REUSE specification.
Fix#16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Unfortunately the fallback configuration code for [mailer] that were
added in #18982 are incorrect. When you read a value from an ini section
that key is added. This leads to a failure of the fallback mechanism.
Further there is also a spelling mistake in the startTLS configuration.
This PR restructures the mailer code to first map the deprecated
settings on to the new ones - and then use ini.MapTo to map those on to
the struct with additional validation as necessary.
Ref #21744
Signed-off-by: Andrew Thornton <art27@cantab.net>
When re-retrieving hook tasks from the DB double check if they have not
been delivered in the meantime. Further ensure that tasks are marked as
delivered when they are being delivered.
In addition:
* Improve the error reporting and make sure that the webhook task
population script runs in a separate goroutine.
* Only get hook task IDs out of the DB instead of the whole task when
repopulating the queue
* When repopulating the queue make the DB request paged
Ref #17940
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Enable this to require captcha validation for user login. You also must
enable `ENABLE_CAPTCHA`.
Summary:
- Consolidate CAPTCHA template
- add CAPTCHA handle and context
- add `REQUIRE_CAPTCHA_FOR_LOGIN` config and docs
- Consolidate CAPTCHA set-up and verification code
Partially resolved#6049
Signed-off-by: Xinyu Zhou <i@sourcehut.net>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Andrew Thornton <art27@cantab.net>
Fix#20456
At some point during the 1.17 cycle abbreviated refishs to issue
branches started breaking. This is likely due serious inconsistencies in
our management of refs throughout Gitea - which is a bug needing to be
addressed in a different PR. (Likely more than one)
We should try to use non-abbreviated `fullref`s as much as possible.
That is where a user has inputted a abbreviated `refish` we should add
`refs/heads/` if it is `branch` etc. I know people keep writing and
merging PRs that remove prefixes from stored content but it is just
wrong and it keeps causing problems like this. We should only remove the
prefix at the time of
presentation as the prefix is the only way of knowing umambiguously and
permanently if the `ref` is referring to a `branch`, `tag` or `commit` /
`SHA`. We need to make it so that every ref has the appropriate prefix,
and probably also need to come up with some definitely unambiguous way
of storing `SHA`s if they're used in a `ref` or `refish` field. We must
not store a potentially
ambiguous `refish` as a `ref`. (Especially when referring a `tag` -
there is no reason why users cannot create a `branch` with the same
short name as a `tag` and vice versa and any attempt to prevent this
will fail. You can even create a `branch` and a
`tag` that matches the `SHA` pattern.)
To that end in order to fix this bug, when parsing issue templates check
the provided `Ref` (here a `refish` because almost all users do not know
or understand the subtly), if it does not start with `refs/` add the
`BranchPrefix` to it. This allows people to make their templates refer
to a `tag` but not to a `SHA` directly. (I don't think that is
particularly unreasonable but if people disagree I can make the `refish`
be checked to see if it matches the `SHA` pattern.)
Next we need to handle the issue links that are already written. The
links here are created with `git.RefURL`
Here we see there is a bug introduced in #17551 whereby the provided
`ref` argument can be double-escaped so we remove the incorrect external
escape. (The escape added in #17551 is in the right place -
unfortunately I missed that the calling function was doing the wrong
thing.)
Then within `RefURL()` we check if an unprefixed `ref` (therefore
potentially a `refish`) matches the `SHA` pattern before assuming that
is actually a `commit` - otherwise is assumed to be a `branch`. This
will handle most of the problem cases excepting the very unusual cases
where someone has deliberately written a `branch` to look like a `SHA1`.
But please if something is called a `ref` or interpreted as a `ref` make
it a full-ref before storing or using it. By all means if something is a
`branch` assume the prefix is removed but always add it back in if you
are using it as a `ref`. Stop storing abbreviated `branch` names and
`tag` names - which are `refish` as a `ref`. It will keep on causing
problems like this.
Fix#20456
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This PR adds a context parameter to a bunch of methods. Some helper
`xxxCtx()` methods got replaced with the normal name now.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
GitHub migration tests will be skipped if the secret for the GitHub API
token hasn't been set.
This change should make all tests pass (or skip in the case of this one)
for anyone running the pipeline on their own infrastructure without
further action on their part.
Resolves https://github.com/go-gitea/gitea/issues/21739
Signed-off-by: Gary Moon <gary@garymoon.net>
The `getPullRequestPayloadInfo` function is widely used in many webhook,
it works well when PR is open or edit. But when we comment in PR review
panel (not PR panel), the comment content is not set as
`attachmentText`.
This commit set comment content as `attachmentText` when PR review, so
webhook could obtain this information via this function.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Fix#19513
This PR introduce a new db method `InTransaction(context.Context)`,
and also builtin check on `db.TxContext` and `db.WithTx`.
There is also a new method `db.AutoTx` has been introduced but could be used by other PRs.
`WithTx` will always open a new transaction, if a transaction exist in context, return an error.
`AutoTx` will try to open a new transaction if no transaction exist in context.
That means it will always enter a transaction if there is no error.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: 6543 <6543@obermui.de>
The purpose of #18982 is to improve the SMTP mailer, but there were some
unrelated changes made to the SMTP auth in
d60c438694
This PR reverts these unrelated changes, fix#21744
Related #20471
This PR adds global quota limits for the package registry. Settings for
individual users/orgs can be added in a seperate PR using the settings
table.
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Close https://github.com/go-gitea/gitea/issues/21640
Before: Gitea can create users like ".xxx" or "x..y", which is not
ideal, it's already a consensus that dot filenames have special
meanings, and `a..b` is a confusing name when doing cross repo compare.
After: stricter
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: delvh <dev.lh@web.de>
_This is a different approach to #20267, I took the liberty of adapting
some parts, see below_
## Context
In some cases, a weebhook endpoint requires some kind of authentication.
The usual way is by sending a static `Authorization` header, with a
given token. For instance:
- Matrix expects a `Bearer <token>` (already implemented, by storing the
header cleartext in the metadata - which is buggy on retry #19872)
- TeamCity #18667
- Gitea instances #20267
- SourceHut https://man.sr.ht/graphql.md#authentication-strategies (this
is my actual personal need :)
## Proposed solution
Add a dedicated encrypt column to the webhook table (instead of storing
it as meta as proposed in #20267), so that it gets available for all
present and future hook types (especially the custom ones #19307).
This would also solve the buggy matrix retry #19872.
As a first step, I would recommend focusing on the backend logic and
improve the frontend at a later stage. For now the UI is a simple
`Authorization` field (which could be later customized with `Bearer` and
`Basic` switches):
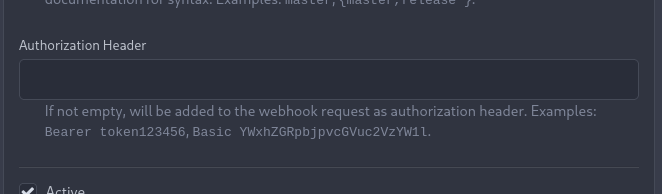
The header name is hard-coded, since I couldn't fine any usecase
justifying otherwise.
## Questions
- What do you think of this approach? @justusbunsi @Gusted @silverwind
- ~~How are the migrations generated? Do I have to manually create a new
file, or is there a command for that?~~
- ~~I started adding it to the API: should I complete it or should I
drop it? (I don't know how much the API is actually used)~~
## Done as well:
- add a migration for the existing matrix webhooks and remove the
`Authorization` logic there
_Closes #19872_
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: Gusted <williamzijl7@hotmail.com>
Co-authored-by: delvh <dev.lh@web.de>
I found myself wondering whether a PR I scheduled for automerge was
actually merged. It was, but I didn't receive a mail notification for it
- that makes sense considering I am the doer and usually don't want to
receive such notifications. But ideally I want to receive a notification
when a PR was merged because I scheduled it for automerge.
This PR implements exactly that.
The implementation works, but I wonder if there's a way to avoid passing
the "This PR was automerged" state down so much. I tried solving this
via the database (checking if there's an automerge scheduled for this PR
when sending the notification) but that did not work reliably, probably
because sending the notification happens async and the entry might have
already been deleted. My implementation might be the most
straightforward but maybe not the most elegant.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
GitHub allows releases with target commitish `refs/heads/BRANCH`, which
then causes issues in Gitea after migration. This fix handles cases that
a branch already has a prefix.
Fixes#20317
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
A bug was introduced in #17865 where filepath.Join is used to join
putative unadopted repository owner and names together. This is
incorrect as these names are then used as repository names - which shoud
have the '/' separator. This means that adoption will not work on
Windows servers.
Fix#21632
Signed-off-by: Andrew Thornton <art27@cantab.net>
The OAuth spec [defines two types of
client](https://datatracker.ietf.org/doc/html/rfc6749#section-2.1),
confidential and public. Previously Gitea assumed all clients to be
confidential.
> OAuth defines two client types, based on their ability to authenticate
securely with the authorization server (i.e., ability to
> maintain the confidentiality of their client credentials):
>
> confidential
> Clients capable of maintaining the confidentiality of their
credentials (e.g., client implemented on a secure server with
> restricted access to the client credentials), or capable of secure
client authentication using other means.
>
> **public
> Clients incapable of maintaining the confidentiality of their
credentials (e.g., clients executing on the device used by the resource
owner, such as an installed native application or a web browser-based
application), and incapable of secure client authentication via any
other means.**
>
> The client type designation is based on the authorization server's
definition of secure authentication and its acceptable exposure levels
of client credentials. The authorization server SHOULD NOT make
assumptions about the client type.
https://datatracker.ietf.org/doc/html/rfc8252#section-8.4
> Authorization servers MUST record the client type in the client
registration details in order to identify and process requests
accordingly.
Require PKCE for public clients:
https://datatracker.ietf.org/doc/html/rfc8252#section-8.1
> Authorization servers SHOULD reject authorization requests from native
apps that don't use PKCE by returning an error message
Fixes#21299
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
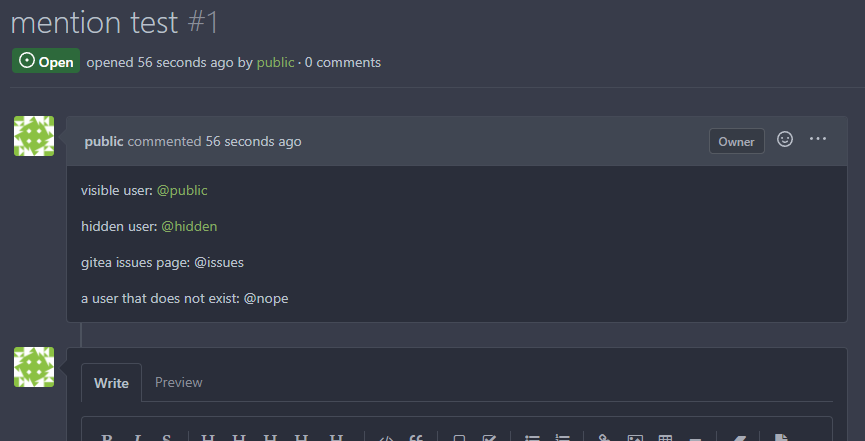
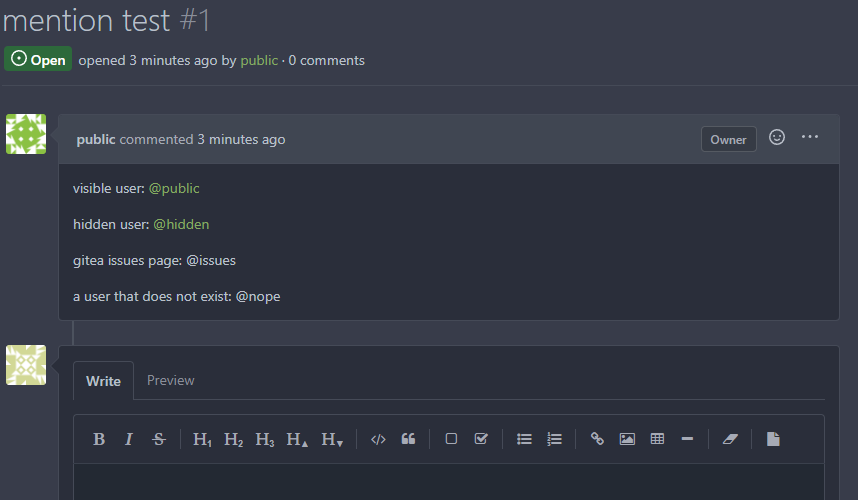
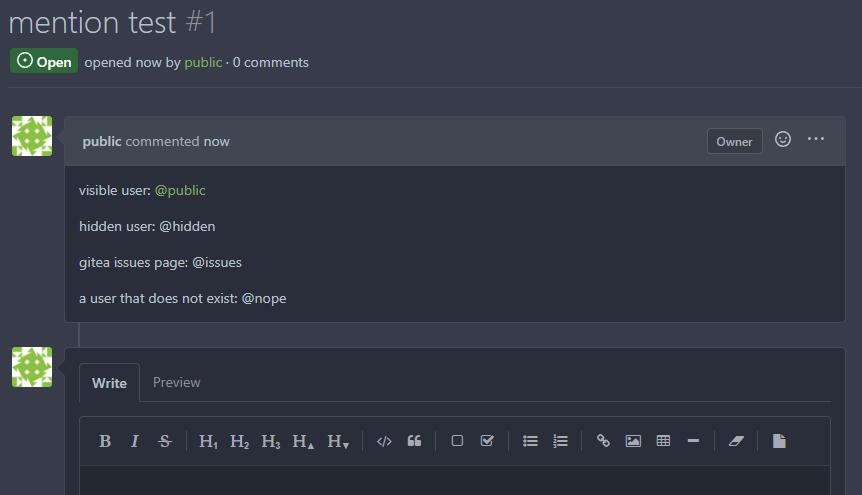
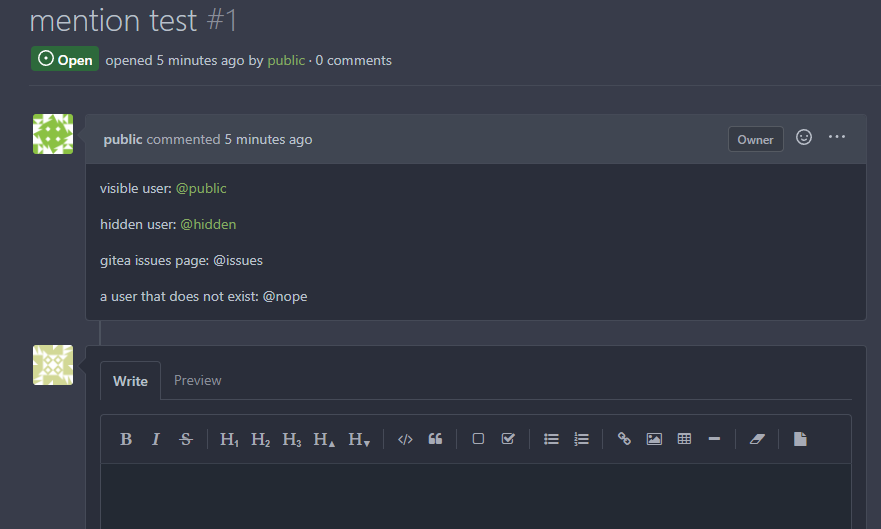
Previously mentioning a user would link to its profile, regardless of
whether the user existed. This change tests if the user exists and only
if it does - a link to its profile is added.
* Fixes#3444
Signed-off-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}