## Changes
- Adds the following high level access scopes, each with `read` and
`write` levels:
- `activitypub`
- `admin` (hidden if user is not a site admin)
- `misc`
- `notification`
- `organization`
- `package`
- `issue`
- `repository`
- `user`
- Adds new middleware function `tokenRequiresScopes()` in addition to
`reqToken()`
- `tokenRequiresScopes()` is used for each high-level api section
- _if_ a scoped token is present, checks that the required scope is
included based on the section and HTTP method
- `reqToken()` is used for individual routes
- checks that required authentication is present (but does not check
scope levels as this will already have been handled by
`tokenRequiresScopes()`
- Adds migration to convert old scoped access tokens to the new set of
scopes
- Updates the user interface for scope selection
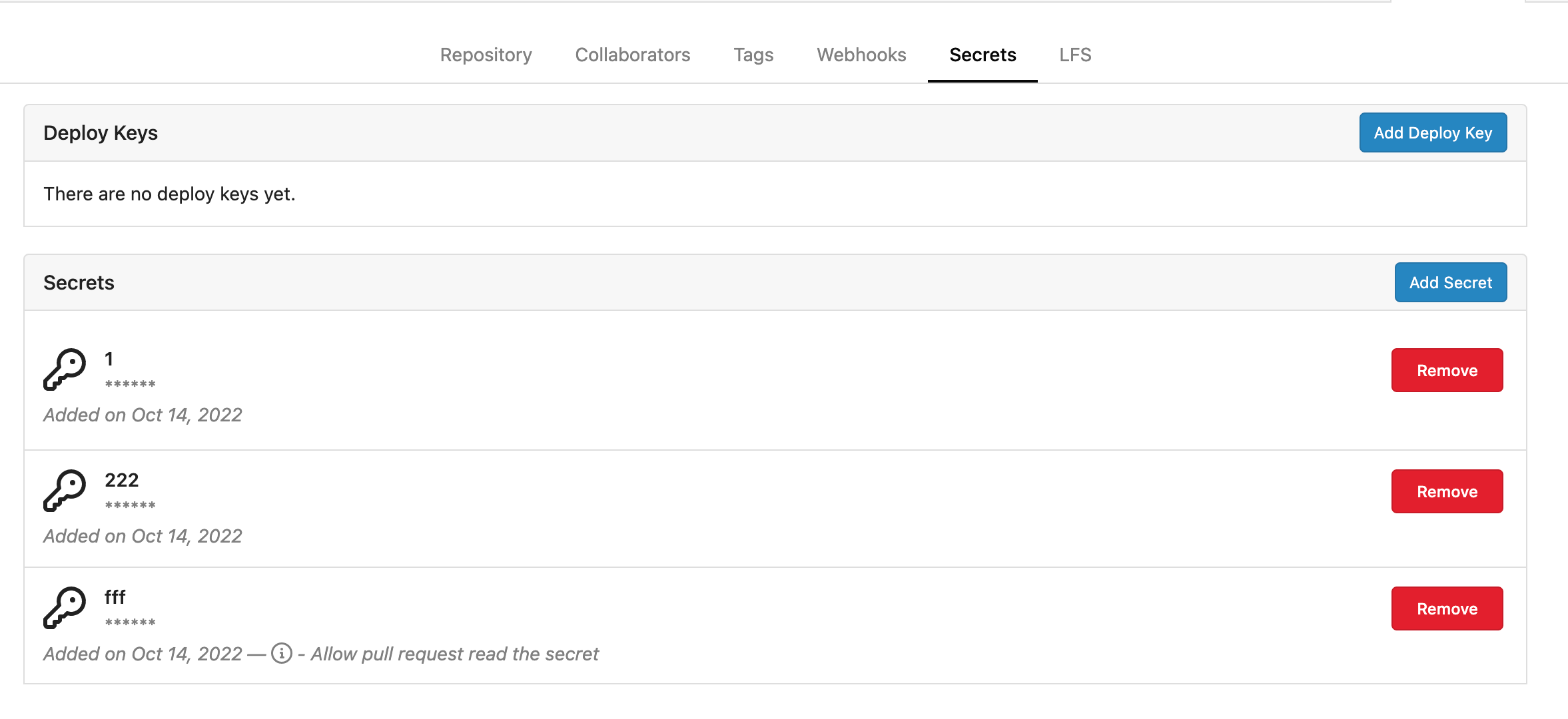
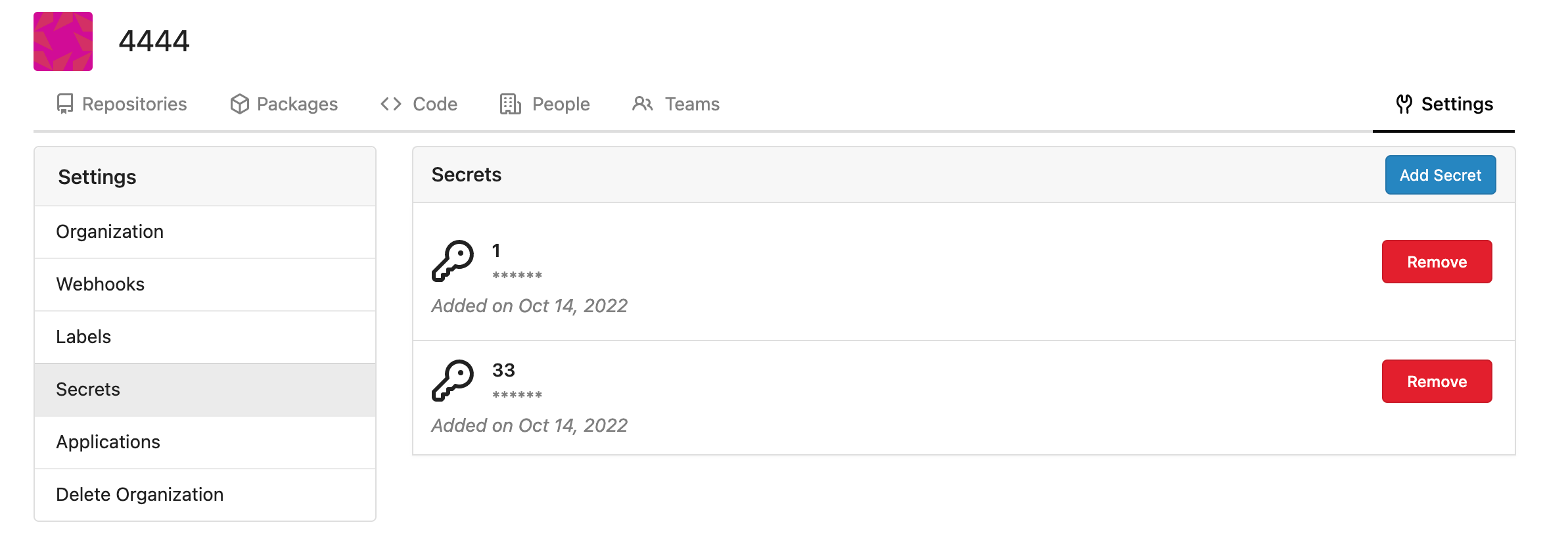
### User interface example
<img width="903" alt="Screen Shot 2023-05-31 at 1 56 55 PM"
src="https://github.com/go-gitea/gitea/assets/23248839/654766ec-2143-4f59-9037-3b51600e32f3">
<img width="917" alt="Screen Shot 2023-05-31 at 1 56 43 PM"
src="https://github.com/go-gitea/gitea/assets/23248839/1ad64081-012c-4a73-b393-66b30352654c">
## tokenRequiresScopes Design Decision
- `tokenRequiresScopes()` was added to more reliably cover api routes.
For an incoming request, this function uses the given scope category
(say `AccessTokenScopeCategoryOrganization`) and the HTTP method (say
`DELETE`) and verifies that any scoped tokens in use include
`delete:organization`.
- `reqToken()` is used to enforce auth for individual routes that
require it. If a scoped token is not present for a request,
`tokenRequiresScopes()` will not return an error
## TODO
- [x] Alphabetize scope categories
- [x] Change 'public repos only' to a radio button (private vs public).
Also expand this to organizations
- [X] Disable token creation if no scopes selected. Alternatively, show
warning
- [x] `reqToken()` is missing from many `POST/DELETE` routes in the api.
`tokenRequiresScopes()` only checks that a given token has the correct
scope, `reqToken()` must be used to check that a token (or some other
auth) is present.
- _This should be addressed in this PR_
- [x] The migration should be reviewed very carefully in order to
minimize access changes to existing user tokens.
- _This should be addressed in this PR_
- [x] Link to api to swagger documentation, clarify what
read/write/delete levels correspond to
- [x] Review cases where more than one scope is needed as this directly
deviates from the api definition.
- _This should be addressed in this PR_
- For example:
```go
m.Group("/users/{username}/orgs", func() {
m.Get("", reqToken(), org.ListUserOrgs)
m.Get("/{org}/permissions", reqToken(), org.GetUserOrgsPermissions)
}, tokenRequiresScopes(auth_model.AccessTokenScopeCategoryUser,
auth_model.AccessTokenScopeCategoryOrganization),
context_service.UserAssignmentAPI())
```
## Future improvements
- [ ] Add required scopes to swagger documentation
- [ ] Redesign `reqToken()` to be opt-out rather than opt-in
- [ ] Subdivide scopes like `repository`
- [ ] Once a token is created, if it has no scopes, we should display
text instead of an empty bullet point
- [ ] If the 'public repos only' option is selected, should read
categories be selected by default
Closes#24501Closes#24799
Co-authored-by: Jonathan Tran <jon@allspice.io>
Co-authored-by: Kyle D <kdumontnu@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
This adds the ability to pin important Issues and Pull Requests. You can
also move pinned Issues around to change their Position. Resolves#2175.
## Screenshots
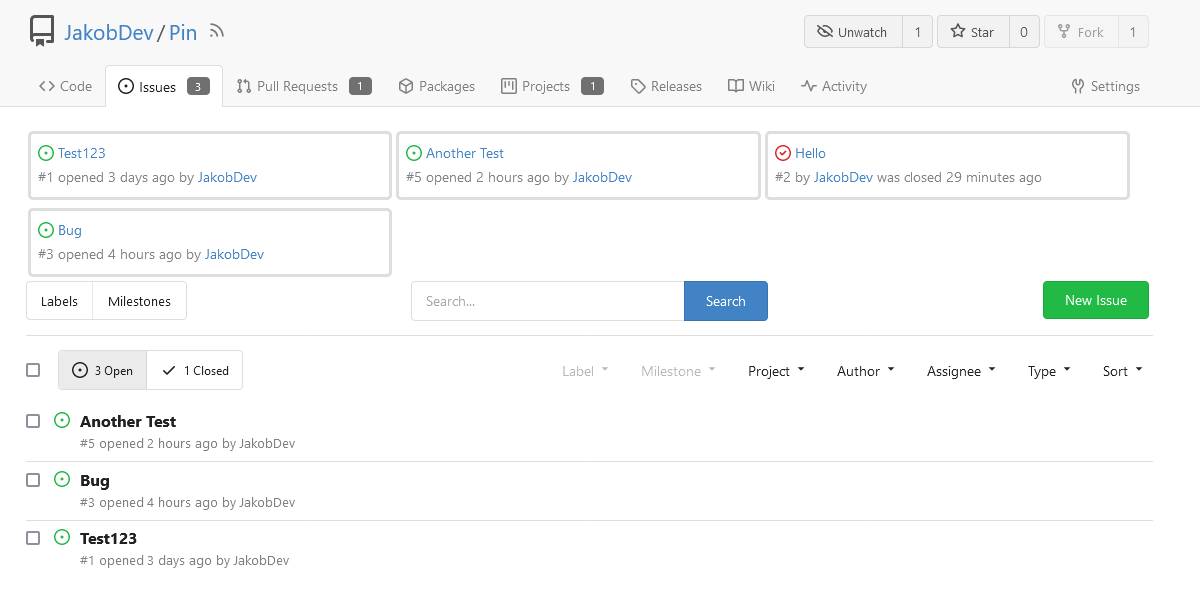
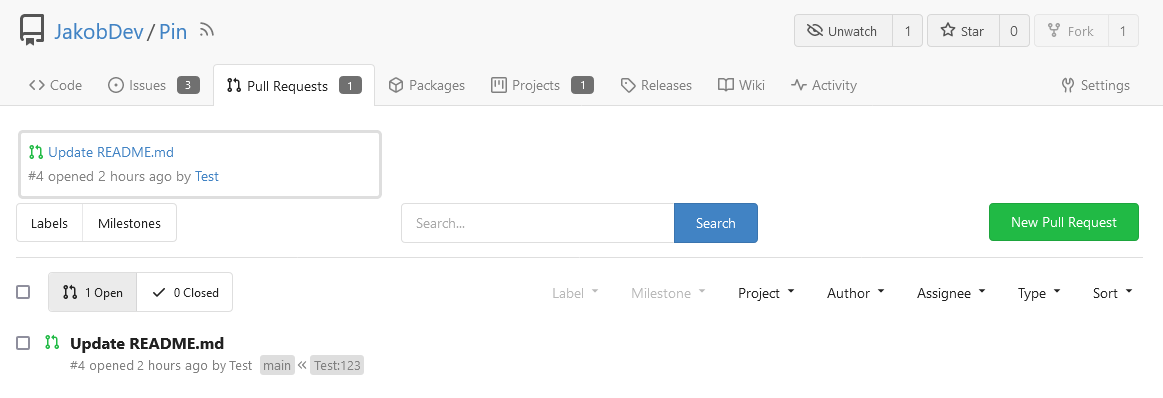
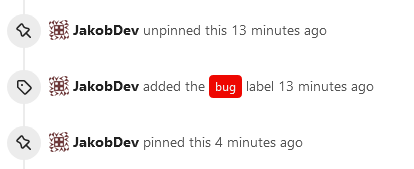
The Design was mostly copied from the Projects Board.
## Implementation
This uses a new `pin_order` Column in the `issue` table. If the value is
set to 0, the Issue is not pinned. If it's set to a bigger value, the
value is the Position. 1 means it's the first pinned Issue, 2 means it's
the second one etc. This is dived into Issues and Pull requests for each
Repo.
## TODO
- [x] You can currently pin as many Issues as you want. Maybe we should
add a Limit, which is configurable. GitHub uses 3, but I prefer 6, as
this is better for bigger Projects, but I'm open for suggestions.
- [x] Pin and Unpin events need to be added to the Issue history.
- [x] Tests
- [x] Migration
**The feature itself is currently fully working, so tester who may find
weird edge cases are very welcome!**
---------
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Giteabot <teabot@gitea.io>
Co-authored-by: @awkwardbunny
This PR adds a Debian package registry. You can follow [this
tutorial](https://www.baeldung.com/linux/create-debian-package) to build
a *.deb package for testing. Source packages are not supported at the
moment and I did not find documentation of the architecture "all" and
how these packages should be treated.
---------
Co-authored-by: Brian Hong <brian@hongs.me>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
A part of https://github.com/go-gitea/gitea/pull/22865
At first, I think we do not need 3 ProjectTypes, as we can check user
type, but it seems that it is not database friendly.
---------
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: 6543 <6543@obermui.de>
Add a new "exclusive" option per label. This makes it so that when the
label is named `scope/name`, no other label with the same `scope/`
prefix can be set on an issue.
The scope is determined by the last occurence of `/`, so for example
`scope/alpha/name` and `scope/beta/name` are considered to be in
different scopes and can coexist.
Exclusive scopes are not enforced by any database rules, however they
are enforced when editing labels at the models level, automatically
removing any existing labels in the same scope when either attaching a
new label or replacing all labels.
In menus use a circle instead of checkbox to indicate they function as
radio buttons per scope. Issue filtering by label ensures that only a
single scoped label is selected at a time. Clicking with alt key can be
used to remove a scoped label, both when editing individual issues and
batch editing.
Label rendering refactor for consistency and code simplification:
* Labels now consistently have the same shape, emojis and tooltips
everywhere. This includes the label list and label assignment menus.
* In label list, show description below label same as label menus.
* Don't use exactly black/white text colors to look a bit nicer.
* Simplify text color computation. There is no point computing luminance
in linear color space, as this is a perceptual problem and sRGB is
closer to perceptually linear.
* Increase height of label assignment menus to show more labels. Showing
only 3-4 labels at a time leads to a lot of scrolling.
* Render all labels with a new RenderLabel template helper function.
Label creation and editing in multiline modal menu:
* Change label creation to open a modal menu like label editing.
* Change menu layout to place name, description and colors on separate
lines.
* Don't color cancel button red in label editing modal menu.
* Align text to the left in model menu for better readability and
consistent with settings layout elsewhere.
Custom exclusive scoped label rendering:
* Display scoped label prefix and suffix with slightly darker and
lighter background color respectively, and a slanted edge between them
similar to the `/` symbol.
* In menus exclusive labels are grouped with a divider line.
---------
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
Unfortunately #20896 does not completely prevent Data too long issues
and GPGKeyImport needs to be increased too.
Fix#22896
Signed-off-by: Andrew Thornton <art27@cantab.net>
Original Issue: https://github.com/go-gitea/gitea/issues/22102
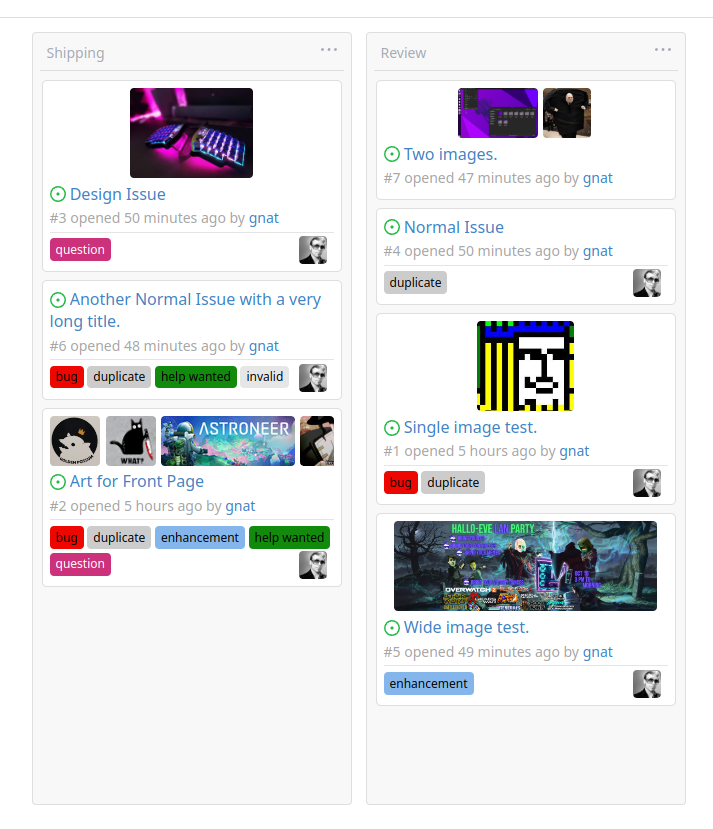
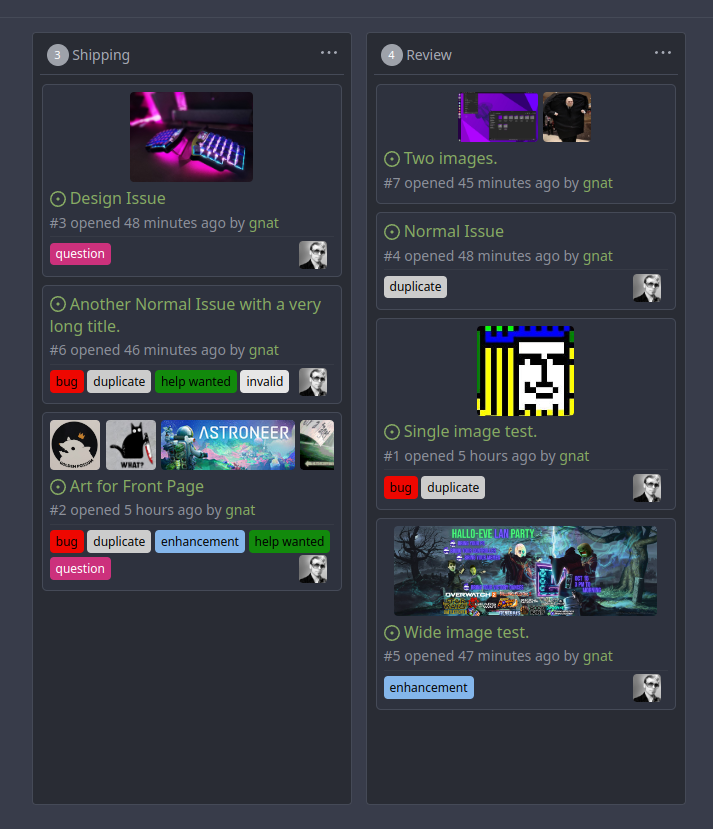
This addition would be a big benefit for design and art teams using the
issue tracking.
The preview will be the latest "image type" attachments on an issue-
simple, and allows for automatic updates of the cover image as issue
progress is made!
This would make Gitea competitive with Trello... wouldn't it be amazing
to say goodbye to Atlassian products? Ha.
First image is the most recent, the SQL will fetch up to 5 latest images
(URL string).
All images supported by browsers plus upcoming formats: *.avif *.bmp
*.gif *.jpg *.jpeg *.jxl *.png *.svg *.webp
The CSS will try to center-align images until it cannot, then it will
left align with overflow hidden. Single images get to be slightly
larger!
Tested so far on: Chrome, Firefox, Android Chrome, Android Firefox.
Current revision with light and dark themes:
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: delvh <dev.lh@web.de>
This PR adds the support for scopes of access tokens, mimicking the
design of GitHub OAuth scopes.
The changes of the core logic are in `models/auth` that `AccessToken`
struct will have a `Scope` field. The normalized (no duplication of
scope), comma-separated scope string will be stored in `access_token`
table in the database.
In `services/auth`, the scope will be stored in context, which will be
used by `reqToken` middleware in API calls. Only OAuth2 tokens will have
granular token scopes, while others like BasicAuth will default to scope
`all`.
A large amount of work happens in `routers/api/v1/api.go` and the
corresponding `tests/integration` tests, that is adding necessary scopes
to each of the API calls as they fit.
- [x] Add `Scope` field to `AccessToken`
- [x] Add access control to all API endpoints
- [x] Update frontend & backend for when creating tokens
- [x] Add a database migration for `scope` column (enable 'all' access
to past tokens)
I'm aiming to complete it before Gitea 1.19 release.
Fixes#4300
This PR adds a task to the cron service to allow garbage collection of
LFS meta objects. As repositories may have a large number of
LFSMetaObjects, an updated column is added to this table and it is used
to perform a generational GC to attempt to reduce the amount of work.
(There may need to be a bit more work here but this is probably enough
for the moment.)
Fix#7045
Signed-off-by: Andrew Thornton <art27@cantab.net>
Some dbs require that all tables have primary keys, see
- #16802
- #21086
We can add a test to keep it from being broken again.
Edit:
~Added missing primary key for `ForeignReference`~ Dropped the
`ForeignReference` table to satisfy the check, so it closes#21086.
More context can be found in comments.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: zeripath <art27@cantab.net>
Change all license headers to comply with REUSE specification.
Fix#16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
_This is a different approach to #20267, I took the liberty of adapting
some parts, see below_
## Context
In some cases, a weebhook endpoint requires some kind of authentication.
The usual way is by sending a static `Authorization` header, with a
given token. For instance:
- Matrix expects a `Bearer <token>` (already implemented, by storing the
header cleartext in the metadata - which is buggy on retry #19872)
- TeamCity #18667
- Gitea instances #20267
- SourceHut https://man.sr.ht/graphql.md#authentication-strategies (this
is my actual personal need :)
## Proposed solution
Add a dedicated encrypt column to the webhook table (instead of storing
it as meta as proposed in #20267), so that it gets available for all
present and future hook types (especially the custom ones #19307).
This would also solve the buggy matrix retry #19872.
As a first step, I would recommend focusing on the backend logic and
improve the frontend at a later stage. For now the UI is a simple
`Authorization` field (which could be later customized with `Bearer` and
`Basic` switches):
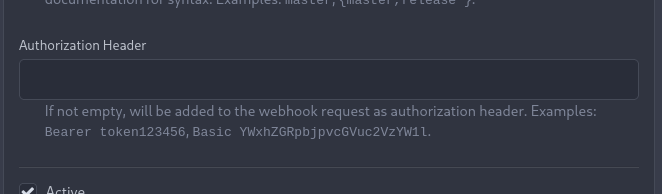
The header name is hard-coded, since I couldn't fine any usecase
justifying otherwise.
## Questions
- What do you think of this approach? @justusbunsi @Gusted @silverwind
- ~~How are the migrations generated? Do I have to manually create a new
file, or is there a command for that?~~
- ~~I started adding it to the API: should I complete it or should I
drop it? (I don't know how much the API is actually used)~~
## Done as well:
- add a migration for the existing matrix webhooks and remove the
`Authorization` logic there
_Closes #19872_
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: Gusted <williamzijl7@hotmail.com>
Co-authored-by: delvh <dev.lh@web.de>
The OAuth spec [defines two types of
client](https://datatracker.ietf.org/doc/html/rfc6749#section-2.1),
confidential and public. Previously Gitea assumed all clients to be
confidential.
> OAuth defines two client types, based on their ability to authenticate
securely with the authorization server (i.e., ability to
> maintain the confidentiality of their client credentials):
>
> confidential
> Clients capable of maintaining the confidentiality of their
credentials (e.g., client implemented on a secure server with
> restricted access to the client credentials), or capable of secure
client authentication using other means.
>
> **public
> Clients incapable of maintaining the confidentiality of their
credentials (e.g., clients executing on the device used by the resource
owner, such as an installed native application or a web browser-based
application), and incapable of secure client authentication via any
other means.**
>
> The client type designation is based on the authorization server's
definition of secure authentication and its acceptable exposure levels
of client credentials. The authorization server SHOULD NOT make
assumptions about the client type.
https://datatracker.ietf.org/doc/html/rfc8252#section-8.4
> Authorization servers MUST record the client type in the client
registration details in order to identify and process requests
accordingly.
Require PKCE for public clients:
https://datatracker.ietf.org/doc/html/rfc8252#section-8.1
> Authorization servers SHOULD reject authorization requests from native
apps that don't use PKCE by returning an error message
Fixes#21299
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
When actions besides "delete" are performed on issues, the milestone
counter is updated. However, since deleting issues goes through a
different code path, the associated milestone's count wasn't being
updated, resulting in inaccurate counts until another issue in the same
milestone had a non-delete action performed on it.
I verified this change fixes the inaccurate counts using a local docker
build.
Fixes#21254
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fixes#21250
Related #20414
Conan packages don't have to follow SemVer.
The migration fixes the setting for all existing Conan and Generic
(#20414) packages.
Unfortunately some keys are too big to fix within the 65535 limit of TEXT on MySQL
this causes issues with these large keys.
Therefore increase these fields to MEDIUMTEXT.
Fix#20894
Signed-off-by: Andrew Thornton <art27@cantab.net>
WebAuthn have updated their specification to set the maximum size of the
CredentialID to 1023 bytes. This is somewhat larger than our current
size and therefore we need to migrate.
The PR changes the struct to add CredentialIDBytes and migrates the CredentialID string
to the bytes field before another migration drops the old CredentialID field. Another migration
renames this field back.
Fix#20457
Signed-off-by: Andrew Thornton <art27@cantab.net>
Support synchronizing with the push mirrors whenever new commits are pushed or synced from pull mirror.
Related Issues: #18220
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Unforunately the previous PR #20035 created indices that were not helpful
for SQLite. This PR adjusts these after testing using the try.gitea.io db.
Fix#20129
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Fix indention
Signed-off-by: kolaente <k@knt.li>
* Add option to merge a pr right now without waiting for the checks to succeed
Signed-off-by: kolaente <k@knt.li>
* Fix lint
Signed-off-by: kolaente <k@knt.li>
* Add scheduled pr merge to tables used for testing
Signed-off-by: kolaente <k@knt.li>
* Add status param to make GetPullRequestByHeadBranch reusable
Signed-off-by: kolaente <k@knt.li>
* Move "Merge now" to a seperate button to make the ui clearer
Signed-off-by: kolaente <k@knt.li>
* Update models/scheduled_pull_request_merge.go
Co-authored-by: 赵智超 <1012112796@qq.com>
* Update web_src/js/index.js
Co-authored-by: 赵智超 <1012112796@qq.com>
* Update web_src/js/index.js
Co-authored-by: 赵智超 <1012112796@qq.com>
* Re-add migration after merge
* Fix frontend lint
* Fix version compare
* Add vendored dependencies
* Add basic tets
* Make sure the api route is capable of scheduling PRs for merging
* Fix comparing version
* make vendor
* adopt refactor
* apply suggestion: User -> Doer
* init var once
* Fix Test
* Update templates/repo/issue/view_content/comments.tmpl
* adopt
* nits
* next
* code format
* lint
* use same name schema; rm CreateUnScheduledPRToAutoMergeComment
* API: can not create schedule twice
* Add TestGetBranchNamesForSha
* nits
* new go routine for each pull to merge
* Update models/pull.go
Co-authored-by: a1012112796 <1012112796@qq.com>
* Update models/scheduled_pull_request_merge.go
Co-authored-by: a1012112796 <1012112796@qq.com>
* fix & add renaming sugestions
* Update services/automerge/pull_auto_merge.go
Co-authored-by: a1012112796 <1012112796@qq.com>
* fix conflict relicts
* apply latest refactors
* fix: migration after merge
* Update models/error.go
Co-authored-by: delvh <dev.lh@web.de>
* Update options/locale/locale_en-US.ini
Co-authored-by: delvh <dev.lh@web.de>
* Update options/locale/locale_en-US.ini
Co-authored-by: delvh <dev.lh@web.de>
* adapt latest refactors
* fix test
* use more context
* skip potential edgecases
* document func usage
* GetBranchNamesForSha() -> GetRefsBySha()
* start refactoring
* ajust to new changes
* nit
* docu nit
* the great check move
* move checks for branchprotection into own package
* resolve todo now ...
* move & rename
* unexport if posible
* fix
* check if merge is allowed before merge on scheduled pull
* debugg
* wording
* improve SetDefaults & nits
* NotAllowedToMerge -> DisallowedToMerge
* fix test
* merge files
* use package "errors"
* merge files
* add string names
* other implementation for gogit
* adapt refactor
* more context for models/pull.go
* GetUserRepoPermission use context
* more ctx
* use context for loading pull head/base-repo
* more ctx
* more ctx
* models.LoadIssueCtx()
* models.LoadIssueCtx()
* Handle pull_service.Merge in one DB transaction
* add TODOs
* next
* next
* next
* more ctx
* more ctx
* Start refactoring structure of old pull code ...
* move code into new packages
* shorter names ... and finish **restructure**
* Update models/branches.go
Co-authored-by: zeripath <art27@cantab.net>
* finish UpdateProtectBranch
* more and fix
* update datum
* template: use "svg" helper
* rename prQueue 2 prPatchCheckerQueue
* handle automerge in queue
* lock pull on git&db actions ...
* lock pull on git&db actions ...
* add TODO notes
* the regex
* transaction in tests
* GetRepositoryByIDCtx
* shorter table name and lint fix
* close transaction bevore notify
* Update models/pull.go
* next
* CheckPullMergable check all branch protections!
* Update routers/web/repo/pull.go
* CheckPullMergable check all branch protections!
* Revert "PullService lock via pullID (#19520)" (for now...)
This reverts commit 6cde7c9159a5ea75a10356feb7b8c7ad4c434a9a.
* Update services/pull/check.go
* Use for a repo action one database transaction
* Apply suggestions from code review
* Apply suggestions from code review
Co-authored-by: delvh <dev.lh@web.de>
* Update services/issue/status.go
Co-authored-by: delvh <dev.lh@web.de>
* Update services/issue/status.go
Co-authored-by: delvh <dev.lh@web.de>
* use db.WithTx()
* gofmt
* make pr.GetDefaultMergeMessage() context aware
* make MergePullRequestForm.SetDefaults context aware
* use db.WithTx()
* pull.SetMerged only with context
* fix deadlock in `test-sqlite\#TestAPIBranchProtection`
* dont forget templates
* db.WithTx allow to set the parentCtx
* handle db transaction in service packages but not router
* issue_service.ChangeStatus just had caused another deadlock :/
it has to do something with how notification package is handled
* if we merge a pull in one database transaktion, we get a lock, because merge infoce internal api that cant handle open db sessions to the same repo
* ajust to current master
* Apply suggestions from code review
Co-authored-by: delvh <dev.lh@web.de>
* dont open db transaction in router
* make generate-swagger
* one _success less
* wording nit
* rm
* adapt
* remove not needed test files
* rm less diff & use attr in JS
* ...
* Update services/repository/files/commit.go
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
* ajust db schema for PullAutoMerge
* skip broken pull refs
* more context in error messages
* remove webUI part for another pull
* remove more WebUI only parts
* API: add CancleAutoMergePR
* Apply suggestions from code review
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
* fix lint
* Apply suggestions from code review
* cancle -> cancel
Co-authored-by: delvh <dev.lh@web.de>
* change queue identifyer
* fix swagger
* prevent nil issue
* fix and dont drop error
* as per @zeripath
* Update integrations/git_test.go
Co-authored-by: delvh <dev.lh@web.de>
* Update integrations/git_test.go
Co-authored-by: delvh <dev.lh@web.de>
* more declarative integration tests (dedup code)
* use assert.False/True helper
Co-authored-by: 赵智超 <1012112796@qq.com>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Adds a feature [like GitHub has](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request-from-a-fork) (step 7).
If you create a new PR from a forked repo, you can select (and change later, but only if you are the PR creator/poster) the "Allow edits from maintainers" option.
Then users with write access to the base branch get more permissions on this branch:
* use the update pull request button
* push directly from the command line (`git push`)
* edit/delete/upload files via web UI
* use related API endpoints
You can't merge PRs to this branch with this enabled, you'll need "full" code write permissions.
This feature has a pretty big impact on the permission system. I might forgot changing some things or didn't find security vulnerabilities. In this case, please leave a review or comment on this PR.
Closes#17728
Co-authored-by: 6543 <6543@obermui.de>
Storing the foreign identifier of an imported issue in the database is a prerequisite to implement idempotent migrations or mirror for issues. It is a baby step towards mirroring that introduces a new table.
At the moment when an issue is created by the Gitea uploader, it fails if the issue already exists. The Gitea uploader could be modified so that, instead of failing, it looks up the database to find an existing issue. And if it does it would update the issue instead of creating a new one. However this is not currently possible because an information is missing from the database: the foreign identifier that uniquely represents the issue being migrated is not persisted. With this change, the foreign identifier is stored in the database and the Gitea uploader will then be able to run a query to figure out if a given issue being imported already exists.
The implementation of mirroring for issues, pull requests, releases, etc. can be done in three steps:
1. Store an identifier for the element being mirrored (issue, pull request...) in the database (this is the purpose of these changes)
2. Modify the Gitea uploader to be able to update an existing repository with all it contains (issues, pull request...) instead of failing if it exists
3. Optimize the Gitea uploader to speed up the updates, when possible.
The second step creates code that does not yet exist to enable idempotent migrations with the Gitea uploader. When a migration is done for the first time, the behavior is not changed. But when a migration is done for a repository that already exists, this new code is used to update it.
The third step can use the code created in the second step to optimize and speed up migrations. For instance, when a migration is resumed, an issue that has an update time that is not more recent can be skipped and only newly created issues or updated ones will be updated. Another example of optimization could be that a webhook notifies Gitea when an issue is updated. The code triggered by the webhook would download only this issue and call the code created in the second step to update the issue, as if it was in the process of an idempotent migration.
The ForeignReferences table is added to contain local and foreign ID pairs relative to a given repository. It can later be used for pull requests and other artifacts that can be mirrored. Although the foreign id could be added as a single field in issues or pull requests, it would need to be added to all tables that represent something that can be mirrored. Creating a new table makes for a simpler and more generic design. The drawback is that it requires an extra lookup to obtain the information. However, this extra information is only required during migration or mirroring and does not impact the way Gitea currently works.
The foreign identifier of an issue or pull request is similar to the identifier of an external user, which is stored in reactions, issues, etc. as OriginalPosterID and so on. The representation of a user is however different and the ability of users to link their account to an external user at a later time is also a logic that is different from what is involved in mirroring or migrations. For these reasons, despite some commonalities, it is unclear at this time how the two tables (foreign reference and external user) could be merged together.
The ForeignID field is extracted from the issue migration context so that it can be dumped in files with dump-repo and later restored via restore-repo.
The GetAllComments downloader method is introduced to simplify the implementation and not overload the Context for the purpose of pagination. It also clarifies in which context the comments are paginated and in which context they are not.
The Context interface is no longer useful for the purpose of retrieving the LocalID and ForeignID since they are now both available from the PullRequest and Issue struct. The Reviewable and Commentable interfaces replace and serve the same purpose.
The Context data member of PullRequest and Issue becomes a DownloaderContext to clarify that its purpose is not to support in memory operations while the current downloader is acting but is not otherwise persisted. It is, for instance, used by the GitLab downloader to store the IsMergeRequest boolean and sort out issues.
---
[source](https://lab.forgefriends.org/forgefriends/forgefriends/-/merge_requests/36)
Signed-off-by: Loïc Dachary <loic@dachary.org>
Co-authored-by: Loïc Dachary <loic@dachary.org>
* Fix page and missing return on unadopted repos API
Page must be 1 if it's not specified and it should return after sending an internal server error.
* Allow ignore pages
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
v208.go is seriously broken as it misses an ID() check. We need to no-op and remigrate all of the u2f keys.
See #18756
Signed-off-by: Andrew Thornton <art27@cantab.net>
Unfortunately credentialIDs in u2f are 255 bytes long which with base32 encoding
becomes 408 bytes. The default size of a xorm string field is only a VARCHAR(255)
This problem is not apparent on SQLite because strings get mapped to TEXT there.
Fix#18727
Signed-off-by: Andrew Thornton <art27@cantab.net>
This contains some additional fixes and small nits related to #17957
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Migrate from U2F to Webauthn
Co-authored-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
* Team permission allow different unit has different permission
* Finish the interface and the logic
* Fix lint
* Fix translation
* align center for table cell content
* Fix fixture
* merge
* Fix test
* Add deprecated
* Improve code
* Add tooltip
* Fix swagger
* Fix newline
* Fix tests
* Fix tests
* Fix test
* Fix test
* Max permission of external wiki and issues should be read
* Move team units with limited max level below units table
* Update label and column names
* Some improvements
* Fix lint
* Some improvements
* Fix template variables
* Add permission docs
* improve doc
* Fix fixture
* Fix bug
* Fix some bug
* fix
* gofumpt
* Integration test for migration (#18124)
integrations: basic test for Gitea {dump,restore}-repo
This is a first step for integration testing of DumpRepository and
RestoreRepository. It:
runs a Gitea server,
dumps a repo via DumpRepository to the filesystem,
restores the repo via RestoreRepository from the filesystem,
dumps the restored repository to the filesystem,
compares the first and second dump and expects them to be identical
The verification is trivial and the goal is to add more tests for each
topic of the dump.
Signed-off-by: Loïc Dachary <loic@dachary.org>
* Team permission allow different unit has different permission
* Finish the interface and the logic
* Fix lint
* Fix translation
* align center for table cell content
* Fix fixture
* merge
* Fix test
* Add deprecated
* Improve code
* Add tooltip
* Fix swagger
* Fix newline
* Fix tests
* Fix tests
* Fix test
* Fix test
* Max permission of external wiki and issues should be read
* Move team units with limited max level below units table
* Update label and column names
* Some improvements
* Fix lint
* Some improvements
* Fix template variables
* Add permission docs
* improve doc
* Fix fixture
* Fix bug
* Fix some bug
* Fix bug
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Aravinth Manivannan <realaravinth@batsense.net>
- The current implementation of `RandomString` doesn't give you a most-possible unique randomness. It gives you 6*`length` instead of the possible 8*`length` bits(or as `length`x bytes) randomness. This is because `RandomString` is being limited to a max value of 63, this in order to represent the random byte as a letter/digit.
- The recommendation of pbkdf2 is to use 64+ bit salt, which the `RandomString` doesn't give with a length of 10, instead of increasing 10 to a higher number, this patch adds a new function called `RandomBytes` which does give you the guarentee of 8*`length` randomness and thus corresponding of `length`x bytes randomness.
- Use hexadecimal to store the bytes value in the database, as mentioned, it doesn't play nice in order to convert it to a string. This will always be a length of 32(with `length` being 16).
- When we detect on `Authenticate`(source: db) that a user has the old format of salt, re-hash the password such that the user will have it's password hashed with increased salt.
Thanks to @zeripath for working out the rouge edges from my first commit 😄.
Co-authored-by: lafriks <lauris@nix.lv>
Co-authored-by: zeripath <art27@cantab.net>
* Add support for ssh commit signing
* Split out ssh verification to separate file
* Show ssh key fingerprint on commit page
* Update sshsig lib
* Make sure we verify against correct namespace
* Add ssh public key verification via ssh signatures
When adding a public ssh key also validate that this user actually
owns the key by signing a token with the private key.
* Remove some gpg references and make verify key optional
* Fix spaces indentation
* Update options/locale/locale_en-US.ini
Co-authored-by: Gusted <williamzijl7@hotmail.com>
* Update templates/user/settings/keys_ssh.tmpl
Co-authored-by: Gusted <williamzijl7@hotmail.com>
* Update options/locale/locale_en-US.ini
Co-authored-by: Gusted <williamzijl7@hotmail.com>
* Update options/locale/locale_en-US.ini
Co-authored-by: Gusted <williamzijl7@hotmail.com>
* Update models/ssh_key_commit_verification.go
Co-authored-by: Gusted <williamzijl7@hotmail.com>
* Reword ssh/gpg_key_success message
* Change Badsignature to NoKeyFound
* Add sign/verify tests
* Fix upstream api changes to user_model User
* Match exact on SSH signature
* Fix code review remarks
Co-authored-by: Gusted <williamzijl7@hotmail.com>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
We have the `AppState` module now, it can store app related data easily. We do not need to create separate tables for each feature.
So the update checker can use `AppState` instead of a one-row dedicate table.
And the code of update checker is moved from `models` to `modules`.
Gitea writes its own AppPath into git hook scripts. If Gitea's AppPath changes, then the git push will fail.
This PR:
* Introduce an AppState module, it can persist app states into database
* During GlobalInit, Gitea will check if the current AppPath is the same as last one. If they don't match, Gitea will sync git hooks.
* Refactor some code to make them more clear.
* Also, "Detect if gitea binary's name changed" #11341 is related, we call models.RewriteAllPublicKeys to update ssh authorized_keys file
* issue content history
* Use timeutil.TimeStampNow() for content history time instead of issue/comment.UpdatedUnix (which are not updated in time)
* i18n for frontend
* refactor
* clean up
* fix refactor
* re-format
* temp refactor
* follow db refactor
* rename IssueContentHistory to ContentHistory, remove empty model tags
* fix html
* use avatar refactor to generate avatar url
* add unit test, keep at most 20 history revisions.
* re-format
* syntax nit
* Add issue content history table
* Update models/migrations/v197.go
Co-authored-by: 6543 <6543@obermui.de>
* fix merge
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Lauris BH <lauris@nix.lv>
- Update default branch if needed
- Update protected branch if needed
- Update all not merged pull request base branch name
- Rename git branch
- Record this rename work and auto redirect for old branch on ui
Signed-off-by: a1012112796 <1012112796@qq.com>
Co-authored-by: delvh <dev.lh@web.de>
* Fix commit status index problem
* remove unused functions
* Add fixture and test for migration
* Fix lint
* Fix fixture
* Fix lint
* Fix test
* Fix bug
* Fix bug
Fixes#16381
Note that changes to unprotected files via the web editor still cannot be pushed directly to the protected branch. I could easily add such support for edits and deletes if needed. But for adding, uploading or renaming unprotected files, it is not trivial.
* Extract & Move GetAffectedFiles to modules/git
When create a new issue or comment and paste/upload an attachment/image, it will not assign an issue id before submit. So if user give up the creating, the attachments will lost key feature and become dirty content. We don't know if we need to delete the attachment even if the repository deleted.
This PR add a repo_id in attachment table so that even if a new upload attachment with no issue_id or release_id but should have repo_id. When deleting a repository, they could also be deleted.
Co-authored-by: 6543 <6543@obermui.de>
Make the group_id a primary key in issue_index. This already has an unique index
and therefore is a good candidate for becoming a primary key.
This PR also changes all other uses of this table to add the group_id as the
primary key.
Fix#16802
Signed-off-by: Andrew Thornton <art27@cantab.net>
The MySQL indexes are not being renamed at the same time as RENAME table despite the
CASCADE. Therefore it is probably better to just recreate the indexes instead.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
* Restore compatibility with SQLServer 2008 R2 in migrations
`ALTER TABLE DROP ... IF EXISTS ...` is only supported in SQL Server >16.
The `IF EXISTS` here is a belt-and-braces and does not need to be present. Therefore
can be dropped.
We need to figure out some way of restricting our SQL syntax against the minimum
version of SQL Server we will support.
My suspicion is that `ALTER DATABASE database_name SET COMPATIBILITY_LEVEL = 100` may
do that but there may be other side-effects so I am not whether to do that.
Signed-off-by: Andrew Thornton <art27@cantab.net>
* try just dropping the index only
Signed-off-by: Andrew Thornton <art27@cantab.net>
* use lowercase for system tables
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
`models` does far too much. In particular it handles all `UserSignin`.
It shouldn't be responsible for calling LDAP, SMTP or PAM for signing in.
Therefore we should move this code out of `models`.
This code has to depend on `models` - therefore it belongs in `services`.
There is a package in `services` called `auth` and clearly this functionality belongs in there.
Plan:
- [x] Change `auth.Auth` to `auth.Method` - as they represent methods of authentication.
- [x] Move `models.UserSignIn` into `auth`
- [x] Move `models.ExternalUserLogin`
- [x] Move most of the `LoginVia*` methods to `auth` or subpackages
- [x] Move Resynchronize functionality to `auth`
- Involved some restructuring of `models/ssh_key.go` to reduce the size of this massive file and simplify its files.
- [x] Move the rest of the LDAP functionality in to the ldap subpackage
- [x] Re-factor the login sources to express an interfaces `auth.Source`?
- I've done this through some smaller interfaces Authenticator and Synchronizable - which would allow us to extend things in future
- [x] Now LDAP is out of models - need to think about modules/auth/ldap and I think all of that functionality might just be moveable
- [x] Similarly a lot Oauth2 functionality need not be in models too and should be moved to services/auth/source/oauth2
- [x] modules/auth/oauth2/oauth2.go uses xorm... This is naughty - probably need to move this into models.
- [x] models/oauth2.go - mostly should be in modules/auth/oauth2 or services/auth/source/oauth2
- [x] More simplifications of login_source.go may need to be done
- Allow wiring in of notify registration - *this can now easily be done - but I think we should do it in another PR* - see #16178
- More refactors...?
- OpenID should probably become an auth Method but I think that can be left for another PR
- Methods should also probably be cleaned up - again another PR I think.
- SSPI still needs more refactors.* Rename auth.Auth auth.Method
* Restructure ssh_key.go
- move functions from models/user.go that relate to ssh_key to ssh_key
- split ssh_key.go to try create clearer function domains for allow for
future refactors here.
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Add option to provide signed token to verify key ownership
Currently we will only allow a key to be matched to a user if it matches
an activated email address. This PR provides a different mechanism - if
the user provides a signature for automatically generated token (based
on the timestamp, user creation time, user ID, username and primary
email.
* Ensure verified keys can act for all active emails for the user
* Add code to mark keys as verified
* Slight UI adjustments
* Slight UI adjustments 2
* Simplify signature verification slightly
* fix postgres test
* add api routes
* handle swapped primary-keys
* Verify the no-reply address for verified keys
* Only add email addresses that are activated to keys
* Fix committer shortcut properly
* Restructure gpg_keys.go
* Use common Verification Token code
Signed-off-by: Andrew Thornton <art27@cantab.net>
This PR removes multiple unneeded fields from the `HookTask` struct and adds the two headers `X-Hub-Signature` and `X-Hub-Signature-256`.
## ⚠️ BREAKING ⚠️
* The `Secret` field is no longer passed as part of the payload.
* "Breaking" change (or fix?): The webhook history shows the real called url and not the url registered in the webhook (`deliver.go`@129).
Close#16115Fixes#7788Fixes#11755
Co-authored-by: zeripath <art27@cantab.net>
* Add migrating message
Signed-off-by: Andrew Thornton <art27@cantab.net>
* simplify messenger
Signed-off-by: Andrew Thornton <art27@cantab.net>
* make messenger an interface
Signed-off-by: Andrew Thornton <art27@cantab.net>
* rename
Signed-off-by: Andrew Thornton <art27@cantab.net>
* prepare for merge
Signed-off-by: Andrew Thornton <art27@cantab.net>
* as per tech
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
* Add a new table issue_index to store the max issue index so that issue could be deleted with no duplicated index
* Fix pull index
* Add tests for concurrent creating issues
* Fix lint
* Fix tests
* Fix postgres test
* Add test for migration v180
* Rename wrong test file name
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Lauris BH <lauris@nix.lv>
* Always store primary email address into email_address table and also the state
* Add lower_email to not convert email to lower as what's added
* Fix fixture
* Fix tests
* Use BeforeInsert to save lower email
* Fix v180 migration
* fix tests
* Fix test
* Remove wrong submited codes
* Fix test
* Fix test
* Fix test
* Add test for v181 migration
* remove change user's email to lower
* Revert change on user's email column
* Fix lower email
* Fix test
* Fix test
* encrypt migration credentials in task persistence
Not sure this is the best approach, we could encrypt the entire
`PayloadContent` instead. Also instead of clearing individual fields in
payload content, we could just delete the task once it has
(successfully) finished..?
* remove credentials of past migrations
* only run DB migration for completed tasks
* fix binding
* add omitempty
* never serialize unencrypted credentials
* fix import order
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
* Refactored handleOAuth2SignIn in routers/user/auth.go
The function handleOAuth2SignIn was called twice but some code path could only
be reached by one of the invocations. Moved the unnecessary code path out of
handleOAuth2SignIn.
* Refactored user creation
There was common code to create a user and display the correct error message.
And after the creation the only user should be an admin and if enabled a
confirmation email should be sent. This common code is now abstracted into
two functions and a helper function to call both.
* Added auto-register for OAuth2 users
If enabled new OAuth2 users will be registered with their OAuth2 details.
The UserID, Name and Email fields from the gothUser are used.
Therefore the OpenID Connect provider needs additional scopes to return
the coresponding claims.
* Added error for missing fields in OAuth2 response
* Linking and auto linking on oauth2 registration
* Set default username source to nickname
* Add automatic oauth2 scopes for github and google
* Add hint to change the openid connect scopes if fields are missing
* Extend info about auto linking security risk
Co-authored-by: Viktor Kuzmin <kvaster@gmail.com>
Signed-off-by: Martin Michaelis <code@mgjm.de>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}