This PR adds `setting.Service.DefaultOrgMemberVisible` value to dataset
of user when the initial org creator is being added to the created org.
Fixes#30012.
This PR will avoid load pullrequest.Issue twice in pull request list
page. It will reduce x times database queries for those WIP pull
requests.
Partially fix#29585
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Fix#29763
This PR fixes 2 problems with CodeOwner in the pull request.
- Don't use the pull request base branch but merge-base as a diff base to
detect the code owner.
- CodeOwner detection in fork repositories will be disabled because
almost all the fork repositories will not change CODEOWNERS files but it
should not be used on fork repositories' pull requests.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
This PR do some performance optimzations.
- [x] Add `index` for the column `comment_id` of `Attachment` table to
accelerate query from the database.
- [x] Remove unnecessary database queries when viewing issues. Before
some conditions which id = 0 will be sent to the database
- [x] Remove duplicated load posters
- [x] Batch loading attachements, isread of comments on viewing issue
---------
Co-authored-by: Zettat123 <zettat123@gmail.com>
This PR do some loading speed optimization for feeds user interface
pages.
- Load action users batchly but not one by one.
- Load action repositories batchly but not one by one.
- Load action's Repo Owners batchly but not one by one.
- Load action's possible issues batchly but not one by one.
- Load action's possible comments batchly but not one by one.
Refactor the webhook logic, to have the type-dependent processing happen
only in one place.
---
## Current webhook flow
1. An event happens
2. It is pre-processed (depending on the webhook type) and its body is
added to a task queue
3. When the task is processed, some more logic (depending on the webhook
type as well) is applied to make an HTTP request
This means that webhook-type dependant logic is needed in step 2 and 3.
This is cumbersome and brittle to maintain.
Updated webhook flow with this PR:
1. An event happens
2. It is stored as-is and added to a task queue
3. When the task is processed, the event is processed (depending on the
webhook type) to make an HTTP request
So the only webhook-type dependent logic happens in one place (step 3)
which should be much more robust.
## Consequences of the refactor
- the raw event must be stored in the hooktask (until now, the
pre-processed body was stored)
- to ensure that previous hooktasks are correctly sent, a
`payload_version` is added (version 1: the body has already been
pre-process / version 2: the body is the raw event)
So future webhook additions will only have to deal with creating an
http.Request based on the raw event (no need to adjust the code in
multiple places, like currently).
Moreover since this processing happens when fetching from the task
queue, it ensures that the queuing of new events (upon a `git push` for
instance) does not get slowed down by a slow webhook.
As a concrete example, the PR #19307 for custom webhooks, should be
substantially smaller:
- no need to change `services/webhook/deliver.go`
- minimal change in `services/webhook/webhook.go` (add the new webhook
to the map)
- no need to change all the individual webhook files (since with this
refactor the `*webhook_model.Webhook` is provided as argument)
The tests on migration tests failed but CI reports successfully
https://github.com/go-gitea/gitea/actions/runs/7364373807/job/20044685969#step:8:141
This PR will fix the bug on migration v283 and also the CI hidden
behaviour.
The reason is on the Makefile
`GITEA_ROOT="$(CURDIR)" GITEA_CONF=tests/mysql.ini $(GO) test
$(GOTESTFLAGS) -tags='$(TEST_TAGS)' $(MIGRATE_TEST_PACKAGES)` will
return the error exit code.
But
`for pkg in $(shell $(GO) list
code.gitea.io/gitea/models/migrations/...); do \
GITEA_ROOT="$(CURDIR)" GITEA_CONF=tests/mysql.ini $(GO) test
$(GOTESTFLAGS) -tags '$(TEST_TAGS)' $$pkg; \
done`
will not work.
This also fix#29602
Unlike other async processing in the queue, we should sync branches to
the DB immediately when handling git hook calling. If it fails, users
can see the error message in the output of the git command.
It can avoid potential inconsistency issues, and help #29494.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fix for regressions introduced by #28805
Enabled projects on repos created before the PR weren't detected. Also,
the way projects mode was detected in settings didn't match the way it
was detected on permission check, which leads to confusion.
Co-authored-by: Giteabot <teabot@gitea.io>
Part of #23318
Add menu in repo settings to allow for repo admin to decide not just if
projects are enabled or disabled per repo, but also which kind of
projects (repo-level/owner-level) are enabled. If repo projects
disabled, don't show the projects tab.
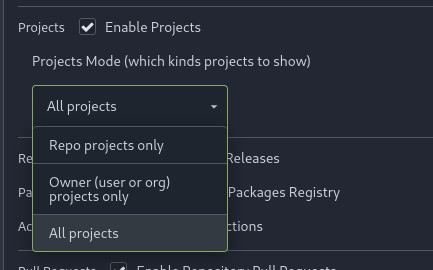
---------
Co-authored-by: delvh <dev.lh@web.de>
To avoid conflicting with User.GetDisplayName, because there is no data
type in template.
And it matches other methods like GetActFullName / GetActUserName
* Follow #17746: `HasIssueContentHistory` should use expr builder to
make sure zero value (0) be respected.
* Add "doer" check to make sure `canSoftDeleteContentHistory` only be
called by sign-in users.
This PR touches the most interesting part of the "template refactoring".
1. Unclear variable type. Especially for "web/feed/convert.go":
sometimes it uses text, sometimes it uses HTML.
2. Assign text content to "RenderedContent" field, for example: `
project.RenderedContent = project.Description` in web/org/projects.go
3. Assign rendered content to text field, for example: `r.Note =
rendered content` in web/repo/release.go
4. (possible) Incorrectly calling `{{Str2html
.PackageDescriptor.Metadata.ReleaseNotes}}` in
package/content/nuget.tmpl, I guess the name Str2html misleads
developers to use it to "render string to html", but it only sanitizes.
if ReleaseNotes really contains HTML, then this is not a problem.
just some refactoring bits towards replacing **util.OptionalBool** with
**optional.Option[bool]**
---------
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Thanks to inferenceus : some sort orders on the "explore/users" page
could list users by their lastlogintime/updatetime.
It leaks user's activity unintentionally. This PR makes that page only
use "supported" sort orders.
Removing the "sort orders" could also be a good solution, while IMO at
the moment keeping the "create time" and "name" orders is also fine, in
case some users would like to find a target user in the search result,
the "sort order" might help.
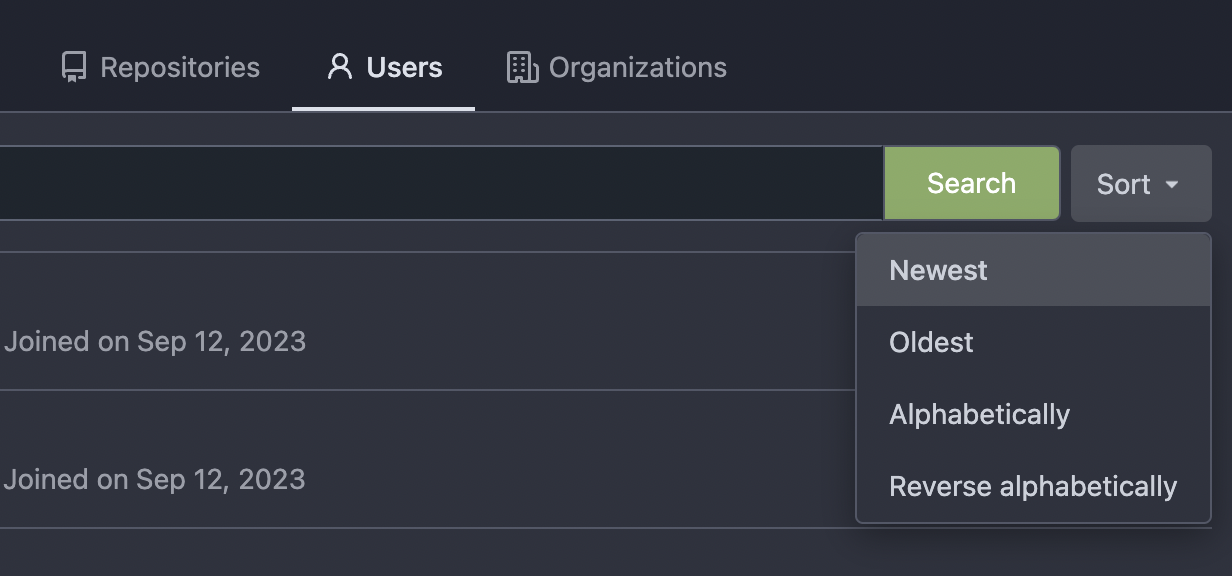
Fix#14459
The following users can add/remove review requests of a PR
- the poster of the PR
- the owner or collaborators of the repository
- members with read permission on the pull requests unit
Adds a new API `/repos/{owner}/{repo}/commits/{sha}/pull` that allows
you to get the merged PR associated to a commit.
---------
Co-authored-by: 6543 <6543@obermui.de>
- Databases are one of the most important parts of Forgejo, every
interaction uses the database in one way or another. Therefore, it is
important to maintain the database and recognize when the server is not
doing well with the database. There already is the option to log *every*
SQL query along with its execution time, but monitoring becomes
impractical for larger instances and takes up unnecessary storage in the
logs.
- Add a QoL enhancement that allows instance administrators to specify a
threshold value beyond which query execution time is logged as a warning
in the xorm logger. The default value is a conservative five seconds to
avoid this becoming a source of spam in the logs.
- The use case for this patch is that with an instance the size of
Codeberg, monitoring SQL logs is not very fruitful and most of them are
uninteresting. Recently, in the context of persistent deadlock issues
(https://codeberg.org/forgejo/forgejo/issues/220), I have noticed that
certain queries hold locks on tables like comment and issue for several
seconds. This patch helps to identify which queries these are and when
they happen.
- Added unit test.
(cherry picked from commit 9cf501f1af4cd870221cef6af489618785b71186)
---------
Co-authored-by: Gusted <postmaster@gusted.xyz>
Co-authored-by: Giteabot <teabot@gitea.io>
Co-authored-by: 6543 <6543@obermui.de>
Clarify when "string" should be used (and be escaped), and when
"template.HTML" should be used (no need to escape)
And help PRs like #29059 , to render the error messages correctly.
With this option, it is possible to require a linear commit history with
the following benefits over the next best option `Rebase+fast-forward`:
The original commits continue existing, with the original signatures
continuing to stay valid instead of being rewritten, there is no merge
commit, and reverting commits becomes easier.
Closes#24906
Commit 360b3fd17c (Include username in email headers (#28981),
2024-02-03) adds usernames to the From field of notification emails in
the form of `Display Name (@username)`, to prevent spoofing. However,
some email filtering software flags "@" in the display name part of the
From field as potential spoofing, as you could set the display name part
to another email address than the one you are sending from (e.g.
`From: "apparent@email-address" <actual@email-address>`). To avoid
being flagged, instead send emails from `Display Name (username)`.
Closes: #29107
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Fixes#28660
Fixes an admin api bug related to `user.LoginSource`
Fixed `/user/emails` response not identical to GitHub api
This PR unifies the user update methods. The goal is to keep the logic
only at one place (having audit logs in mind). For example, do the
password checks only in one method not everywhere a password is updated.
After that PR is merged, the user creation should be next.
Emails from Gitea comments do not contain the username of the commenter
anywhere, only their display name, so it is not possible to verify who
made a comment from the email itself:
From: "Alice" <email@gitea>
X-Gitea-Sender: Alice
X-Gitea-Recipient: Bob
X-GitHub-Sender: Alice
X-GitHub-Recipient: Bob
This comment looks like it's from @alice.
The X-Gitea/X-GitHub headers also use display names, which is not very
reliable for filtering, and inconsistent with GitHub's behavior:
X-GitHub-Sender: lunny
X-GitHub-Recipient: gwymor
This change includes both the display name and username in the From
header, and switches the other headers from display name to username:
From: "Alice (@fakealice)" <email@gitea>
X-Gitea-Sender: fakealice
X-Gitea-Recipient: bob
X-GitHub-Sender: fakealice
X-GitHub-Recipient: bob
This comment looks like it's from @alice.
## Purpose
This is a refactor toward building an abstraction over managing git
repositories.
Afterwards, it does not matter anymore if they are stored on the local
disk or somewhere remote.
## What this PR changes
We used `git.OpenRepository` everywhere previously.
Now, we should split them into two distinct functions:
Firstly, there are temporary repositories which do not change:
```go
git.OpenRepository(ctx, diskPath)
```
Gitea managed repositories having a record in the database in the
`repository` table are moved into the new package `gitrepo`:
```go
gitrepo.OpenRepository(ctx, repo_model.Repo)
```
Why is `repo_model.Repository` the second parameter instead of file
path?
Because then we can easily adapt our repository storage strategy.
The repositories can be stored locally, however, they could just as well
be stored on a remote server.
## Further changes in other PRs
- A Git Command wrapper on package `gitrepo` could be created. i.e.
`NewCommand(ctx, repo_model.Repository, commands...)`. `git.RunOpts{Dir:
repo.RepoPath()}`, the directory should be empty before invoking this
method and it can be filled in the function only. #28940
- Remove the `RepoPath()`/`WikiPath()` functions to reduce the
possibility of mistakes.
---------
Co-authored-by: delvh <dev.lh@web.de>
Fixes#22236
---
Error occurring currently while trying to revert commit using read-tree
-m approach:
> 2022/12/26 16:04:43 ...rvices/pull/patch.go:240:AttemptThreeWayMerge()
[E] [63a9c61a] Unable to run read-tree -m! Error: exit status 128 -
fatal: this operation must be run in a work tree
> - fatal: this operation must be run in a work tree
We need to clone a non-bare repository for `git read-tree -m` to work.
bb371aee6e
adds support to create a non-bare cloned temporary upload repository.
After cloning a non-bare temporary upload repository, we [set default
index](https://github.com/go-gitea/gitea/blob/main/services/repository/files/cherry_pick.go#L37)
(`git read-tree HEAD`).
This operation ends up resetting the git index file (see investigation
details below), due to which, we need to call `git update-index
--refresh` afterward.
Here's the diff of the index file before and after we execute
SetDefaultIndex: https://www.diffchecker.com/hyOP3eJy/
Notice the **ctime**, **mtime** are set to 0 after SetDefaultIndex.
You can reproduce the same behavior using these steps:
```bash
$ git clone https://try.gitea.io/me-heer/test.git -s -b main
$ cd test
$ git read-tree HEAD
$ git read-tree -m 1f085d7ed8 1f085d7ed8 9933caed00
error: Entry '1' not uptodate. Cannot merge.
```
After which, we can fix like this:
```
$ git update-index --refresh
$ git read-tree -m 1f085d7ed8 1f085d7ed8 9933caed00
```
By clicking the currently active "Open" or "Closed" filter button in the
issue list, the user can toggle that filter off in order to see all
issues regardless of state. The URL "state" parameter will be set to
"all" and the "Open"/"Closed" button will not show as active.
Fixes#26548
This PR refactors the rendering of markup links. The old code uses
`strings.Replace` to change some urls while the new code uses more
context to decide which link should be generated.
The added tests should ensure the same output for the old and new
behaviour (besides the bug).
We may need to refactor the rendering a bit more to make it clear how
the different helper methods render the input string. There are lots of
options (resolve links / images / mentions / git hashes / emojis / ...)
but you don't really know what helper uses which options. For example,
we currently support images in the user description which should not be
allowed I think:
<details>
<summary>Profile</summary>
https://try.gitea.io/KN4CK3R

</details>
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Fixes#27114.
* In Gitea 1.12 (#9532), a "dismiss stale approvals" branch protection
setting was introduced, for ignoring stale reviews when verifying the
approval count of a pull request.
* In Gitea 1.14 (#12674), the "dismiss review" feature was added.
* This caused confusion with users (#25858), as "dismiss" now means 2
different things.
* In Gitea 1.20 (#25882), the behavior of the "dismiss stale approvals"
branch protection was modified to actually dismiss the stale review.
For some users this new behavior of dismissing the stale reviews is not
desirable.
So this PR reintroduces the old behavior as a new "ignore stale
approvals" branch protection setting.
---------
Co-authored-by: delvh <dev.lh@web.de>
Fix#28157
This PR fix the possible bugs about actions schedule.
## The Changes
- Move `UpdateRepositoryUnit` and `SetRepoDefaultBranch` from models to
service layer
- Remove schedules plan from database and cancel waiting & running
schedules tasks in this repository when actions unit has been disabled
or global disabled.
- Remove schedules plan from database and cancel waiting & running
schedules tasks in this repository when default branch changed.
Mainly for MySQL/MSSQL.
It is important for Gitea to use case-sensitive database charset
collation. If the database is using a case-insensitive collation, Gitea
will show startup error/warning messages, and show the errors/warnings
on the admin panel's Self-Check page.
Make `gitea doctor convert` work for MySQL to convert the collations of
database & tables & columns.
* Fix#28131
## ⚠️ BREAKING ⚠️
It is not quite breaking, but it's highly recommended to convert the
database&table&column to a consistent and case-sensitive collation.
Fix https://github.com/go-gitea/gitea/pull/28547#issuecomment-1867740842
Since https://gitea.com/xorm/xorm/pulls/2383 merged, xorm now supports
UPDATE JOIN.
To keep consistent from different databases, xorm use
`engine.Join().Update`, but the actural generated SQL are different
between different databases.
For MySQL, it's `UPDATE talbe1 JOIN table2 ON join_conditions SET xxx
Where xxx`.
For MSSQL, it's `UPDATE table1 SET xxx FROM TABLE1, TABLE2 WHERE
join_conditions`.
For SQLITE per https://www.sqlite.org/lang_update.html, sqlite support
`UPDATE table1 SET xxx FROM table2 WHERE join conditions` from
3.33.0(2020-8-14).
POSTGRES is the same as SQLITE.
This is a regression from #28220 .
`builder.Cond` will not add `` ` `` automatically but xorm method
`Get/Find` adds `` ` ``.
This PR also adds tests to prevent the method from being implemented
incorrectly. The tests are added in `integrations` to test every
database.
Introduce the new generic deletion methods
- `func DeleteByID[T any](ctx context.Context, id int64) (int64, error)`
- `func DeleteByIDs[T any](ctx context.Context, ids ...int64) error`
- `func Delete[T any](ctx context.Context, opts FindOptions) (int64,
error)`
So, we no longer need any specific deletion method and can just use
the generic ones instead.
Replacement of #28450Closes#28450
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This reverts commit b35d3fddfa.
This is totally wrong. I think `Update join` hasn't been supported well
by xorm.
I just revert the PR and will try to send another one.
Using the Go Official tool `golang.org/x/tools/cmd/deadcode@latest`
mentioned by [go blog](https://go.dev/blog/deadcode).
Just use `deadcode .` in the project root folder and it gives a list of
unused functions. Though it has some false alarms.
This PR removes dead code detected in `models/issues`.
The 4 functions are duplicated, especially as interface methods. I think
we just need to keep `MustID` the only one and remove other 3.
```
MustID(b []byte) ObjectID
MustIDFromString(s string) ObjectID
NewID(b []byte) (ObjectID, error)
NewIDFromString(s string) (ObjectID, error)
```
Introduced the new interfrace method `ComputeHash` which will replace
the interface `HasherInterface`. Now we don't need to keep two
interfaces.
Reintroduced `git.NewIDFromString` and `git.MustIDFromString`. The new
function will detect the hash length to decide which objectformat of it.
If it's 40, then it's SHA1. If it's 64, then it's SHA256. This will be
right if the commitID is a full one. So the parameter should be always a
full commit id.
@AdamMajer Please review.
- If a topic has zero repository count, it means that none of the
repositories are using that topic, that would make them 'useless' to
keep. One caveat is that if that topic is going to be used in the
future, it will be added again to the database, but simply with a new
ID.
Refs: https://codeberg.org/forgejo/forgejo/pulls/1964
Co-authored-by: Gusted <postmaster@gusted.xyz>
- Remove `ObjectFormatID`
- Remove function `ObjectFormatFromID`.
- Use `Sha1ObjectFormat` directly but not a pointer because it's an
empty struct.
- Store `ObjectFormatName` in `repository` struct
Windows-based shells will add a CRLF when piping the token into
ssh-keygen command resulting in
verification error. This resolves#21527.
---------
Co-authored-by: Heiko Besemann <heiko.besemann@qbeyond.de>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Refactor Hash interfaces and centralize hash function. This will allow
easier introduction of different hash function later on.
This forms the "no-op" part of the SHA256 enablement patch.
Fix#28056
This PR will check whether the repo has zero branch when pushing a
branch. If that, it means this repository hasn't been synced.
The reason caused that is after user upgrade from v1.20 -> v1.21, he
just push branches without visit the repository user interface. Because
all repositories routers will check whether a branches sync is necessary
but push has not such check.
For every repository, it has two states, synced or not synced. If there
is zero branch for a repository, then it will be assumed as non-sync
state. Otherwise, it's synced state. So if we think it's synced, we just
need to update branch/insert new branch. Otherwise do a full sync. So
that, for every push, there will be almost no extra load added. It's
high performance than yours.
For the implementation, we in fact will try to update the branch first,
if updated success with affect records > 0, then all are done. Because
that means the branch has been in the database. If no record is
affected, that means the branch does not exist in database. So there are
two possibilities. One is this is a new branch, then we just need to
insert the record. Another is the branches haven't been synced, then we
need to sync all the branches into database.
The function `GetByBean` has an obvious defect that when the fields are
empty values, it will be ignored. Then users will get a wrong result
which is possibly used to make a security problem.
To avoid the possibility, this PR removed function `GetByBean` and all
references.
And some new generic functions have been introduced to be used.
The recommand usage like below.
```go
// if query an object according id
obj, err := db.GetByID[Object](ctx, id)
// query with other conditions
obj, err := db.Get[Object](ctx, builder.Eq{"a": a, "b":b})
```
It will fix#28268 .
<img width="1313" alt="image"
src="https://github.com/go-gitea/gitea/assets/9418365/cb1e07d5-7a12-4691-a054-8278ba255bfc">
<img width="1318" alt="image"
src="https://github.com/go-gitea/gitea/assets/9418365/4fd60820-97f1-4c2c-a233-d3671a5039e9">
## ⚠️ BREAKING ⚠️
But need to give up some features:
<img width="1312" alt="image"
src="https://github.com/go-gitea/gitea/assets/9418365/281c0d51-0e7d-473f-bbed-216e2f645610">
However, such abandonment may fix#28055 .
## Backgroud
When the user switches the dashboard context to an org, it means they
want to search issues in the repos that belong to the org. However, when
they switch to themselves, it means all repos they can access because
they may have created an issue in a public repo that they don't own.
<img width="286" alt="image"
src="https://github.com/go-gitea/gitea/assets/9418365/182dcd5b-1c20-4725-93af-96e8dfae5b97">
It's a confusing design. Think about this: What does "In your
repositories" mean when the user switches to an org? Repos belong to the
user or the org?
Whatever, it has been broken by #26012 and its following PRs. After the
PR, it searches for issues in repos that the dashboard context user owns
or has been explicitly granted access to, so it causes #28268.
## How to fix it
It's not really difficult to fix it. Just extend the repo scope to
search issues when the dashboard context user is the doer. Since the
user may create issues or be mentioned in any public repo, we can just
set `AllPublic` to true, which is already supported by indexers. The DB
condition will also support it in this PR.
But the real difficulty is how to count the search results grouped by
repos. It's something like "search issues with this keyword and those
filters, and return the total number and the top results. **Then, group
all of them by repo and return the counts of each group.**"
<img width="314" alt="image"
src="https://github.com/go-gitea/gitea/assets/9418365/5206eb20-f8f5-49b9-b45a-1be2fcf679f4">
Before #26012, it was being done in the DB, but it caused the results to
be incomplete (see the description of #26012).
And to keep this, #26012 implement it in an inefficient way, just count
the issues by repo one by one, so it cannot work when `AllPublic` is
true because it's almost impossible to do this for all public repos.
1bfcdeef4c/modules/indexer/issues/indexer.go (L318-L338)
## Give up unnecessary features
We may can resovle `TODO: use "group by" of the indexer engines to
implement it`, I'm sure it can be done with Elasticsearch, but IIRC,
Bleve and Meilisearch don't support "group by".
And the real question is, does it worth it? Why should we need to know
the counts grouped by repos?
Let me show you my search dashboard on gitea.com.
<img width="1304" alt="image"
src="https://github.com/go-gitea/gitea/assets/9418365/2bca2d46-6c71-4de1-94cb-0c9af27c62ff">
I never think the long repo list helps anything.
And if we agree to abandon it, things will be much easier. That is this
PR.
## TODO
I know it's important to filter by repos when searching issues. However,
it shouldn't be the way we have it now. It could be implemented like
this.
<img width="1316" alt="image"
src="https://github.com/go-gitea/gitea/assets/9418365/99ee5f21-cbb5-4dfe-914d-cb796cb79fbe">
The indexers support it well now, but it requires some frontend work,
which I'm not good at. So, I think someone could help do that in another
PR and merge this one to fix the bug first.
Or please block this PR and help to complete it.
Finally, "Switch dashboard context" is also a design that needs
improvement. In my opinion, it can be accomplished by adding filtering
conditions instead of "switching".
When we pick up a job, all waiting jobs should firstly be ordered by
update time,
otherwise when there's a running job, if I rerun an older job, the older
job will run first, as it's id is smaller.
This resolves a problem I encountered while updating gitea from 1.20.4
to 1.21. For some reason (correct or otherwise) there are some values in
`repository.size` that are NULL in my gitea database which cause this
migration to fail due to the NOT NULL constraints.
Log snippet (excuse the escape characters)
```
ESC[36mgitea |ESC[0m 2023-12-04T03:52:28.573122395Z 2023/12/04 03:52:28 ...ations/migrations.go:641:Migrate() [I] Migration[263]: Add git_size and lfs_size columns to repository table
ESC[36mgitea |ESC[0m 2023-12-04T03:52:28.608705544Z 2023/12/04 03:52:28 routers/common/db.go:36:InitDBEngine() [E] ORM engine initialization attempt #3/10 failed. Error: migrate: migration[263]: Add git_size and lfs_size columns to repository table failed: NOT NULL constraint failed: repository.git_size
```
I assume this should be reasonably safe since `repository.git_size` has
a default value of 0 but I don't know if that value being 0 in the odd
situation where `repository.size == NULL` has any problematic
consequences.
- Currently the repository description uses the same sanitizer as a
normal markdown document. This means that element such as heading and
images are allowed and can be abused.
- Create a minimal restricted sanitizer for the repository description,
which only allows what the postprocessor currently allows, which are
links and emojis.
- Added unit testing.
- Resolves https://codeberg.org/forgejo/forgejo/issues/1202
- Resolves https://codeberg.org/Codeberg/Community/issues/1122
(cherry picked from commit 631c87cc2347f0036a75dcd21e24429bbca28207)
Co-authored-by: Gusted <postmaster@gusted.xyz>
Changed behavior to calculate package quota limit using package `creator
ID` instead of `owner ID`.
Currently, users are allowed to create an unlimited number of
organizations, each of which has its own package limit quota, resulting
in the ability for users to have unlimited package space in different
organization scopes. This fix will calculate package quota based on
`package version creator ID` instead of `package version owner ID`
(which might be organization), so that users are not allowed to take
more space than configured package settings.
Also, there is a side case in which users can publish packages to a
specific package version, initially published by different user, taking
that user package size quota. Version in fix should be better because
the total amount of space is limited to the quota for users sharing the
same organization scope.
System users (Ghost, ActionsUser, etc) have a negative id and may be the
author of a comment, either because it was created by a now deleted user
or via an action using a transient token.
The GetPossibleUserByID function has special cases related to system
users and will not fail if given a negative id.
Refs: https://codeberg.org/forgejo/forgejo/issues/1425
(cherry picked from commit 6a2d2fa24390116d31ae2507c0a93d423f690b7b)
Fixes https://codeberg.org/forgejo/forgejo/issues/1458
Some mails such as issue creation mails are missing the reply-to-comment
address. This PR fixes that and specifies which comment types should get
a reply-possibility.
## Bug in Gitea
I ran into this bug when I accidentally used the wrong redirect URL for
the oauth2 provider when using mssql. But the oauth2 provider still got
added.
Most of the time, we use `Delete(&some{id: some.id})` or
`In(condition).Delete(&some{})`, which specify the conditions. But the
function uses `Delete(source)` when `source.Cfg` is a `TEXT` field and
not empty. This will cause xorm `Delete` function not working in mssql.
61ff91f960/models/auth/source.go (L234-L240)
## Reason
Because the `TEXT` field can not be compared in mssql, xorm doesn't
support it according to [this
PR](https://gitea.com/xorm/xorm/pulls/2062)
[related
code](b23798dc98/internal/statements/statement.go (L552-L558))
in xorm
```go
if statement.dialect.URI().DBType == schemas.MSSQL && (col.SQLType.Name == schemas.Text ||
col.SQLType.IsBlob() || col.SQLType.Name == schemas.TimeStampz) {
if utils.IsValueZero(fieldValue) {
continue
}
return nil, fmt.Errorf("column %s is a TEXT type with data %#v which cannot be as compare condition", col.Name, fieldValue.Interface())
}
}
```
When using the `Delete` function in xorm, the non-empty fields will
auto-set as conditions(perhaps some special fields are not?). If `TEXT`
field is not empty, xorm will return an error. I only found this usage
after searching, but maybe there is something I missing.
---------
Co-authored-by: delvh <dev.lh@web.de>
- On user deletion, delete action runners that the user has created.
- Add a database consistency check to remove action runners that have
nonexistent belonging owner.
- Resolves https://codeberg.org/forgejo/forgejo/issues/1720
(cherry picked from commit 009ca7223dab054f7f760b7ccae69e745eebfabb)
Co-authored-by: Gusted <postmaster@gusted.xyz>
The steps to reproduce it.
First, create a new oauth2 source.
Then, a user login with this oauth2 source.
Disable the oauth2 source.
Visit users -> settings -> security, 500 will be displayed.
This is because this page only load active Oauth2 sources but not all
Oauth2 sources.
See https://github.com/go-gitea/gitea/pull/27718#issuecomment-1773743014
. Add a test to ensure its behavior.
Why this test uses `ProjectBoardID=0`? Because in `SearchOptions`,
`ProjectBoardID=0` means what it is. But in `IssueOptions`,
`ProjectBoardID=0` means there is no condition, and
`ProjectBoardID=db.NoConditionID` means the board ID = 0.
It's really confusing. Probably it's better to separate the db search
engine and the other issue search code. It's really two different
systems. As far as I can see, `IssueOptions` is not necessary for most
of the code, which has very simple issue search conditions.
1. remove unused function `MoveIssueAcrossProjectBoards`
2. extract the project board condition into a function
3. use db.NoCondition instead of -1. (BTW, the usage of db.NoCondition
is too confusing. Is there any way to avoid that?)
4. remove the unnecessary comment since the ctx refactor is completed.
5. Change `b.ID != 0` to `b.ID > 0`. It's more intuitive but I think
they're the same since board ID can't be negative.
Closes#27455
> The mechanism responsible for long-term authentication (the 'remember
me' cookie) uses a weak construction technique. It will hash the user's
hashed password and the rands value; it will then call the secure cookie
code, which will encrypt the user's name with the computed hash. If one
were able to dump the database, they could extract those two values to
rebuild that cookie and impersonate a user. That vulnerability exists
from the date the dump was obtained until a user changed their password.
>
> To fix this security issue, the cookie could be created and verified
using a different technique such as the one explained at
https://paragonie.com/blog/2015/04/secure-authentication-php-with-long-term-persistence#secure-remember-me-cookies.
The PR removes the now obsolete setting `COOKIE_USERNAME`.