There are still some functions under `models` after last big refactor
about `models`. This change will move all team related functions to
service layer with no code change.
## Solves
Currently for rules to re-order them you have to alter the creation
date. so you basicly have to delete and recreate them in the right
order. This is more than just inconvinient ...
## Solution
Add a new col for prioritization
## Demo WebUI Video
https://github.com/user-attachments/assets/92182a31-9705-4ac5-b6e3-9bb74108cbd1
---
*Sponsored by Kithara Software GmbH*
This PR mainly removes some global variables, moves some code and
renames some functions to make code clearer.
This PR also removes a testing-only option ForceHardLineBreak during
refactoring since the behavior is clear now.
This PR removes (almost) all path tricks, and introduces "renderhelper"
package.
Now we can clearly see the rendering behaviors for comment/file/wiki,
more details are in "renderhelper" tests.
Fix#31411 , fix#18592, fix#25632 and maybe more problems. (ps: fix
#32608 by the way)
This PR rewrites `GetReviewer` function and move it to service layer.
Reviewers should not be watchers, so that this PR removed all watchers
from reviewers. When the repository is under an organization, the pull
request unit read permission will be checked to resolve the bug of
#32394Fix#32394
Resolve#31609
This PR was initiated following my personal research to find the
lightest possible Single Sign-On solution for self-hosted setups. The
existing solutions often seemed too enterprise-oriented, involving many
moving parts and services, demanding significant resources while
promising planetary-scale capabilities. Others were adequate in
supporting basic OAuth2 flows but lacked proper user management
features, such as a change password UI.
Gitea hits the sweet spot for me, provided it supports more granular
access permissions for resources under users who accept the OAuth2
application.
This PR aims to introduce granularity in handling user resources as
nonintrusively and simply as possible. It allows third parties to inform
users about their intent to not ask for the full access and instead
request a specific, reduced scope. If the provided scopes are **only**
the typical ones for OIDC/OAuth2—`openid`, `profile`, `email`, and
`groups`—everything remains unchanged (currently full access to user's
resources). Additionally, this PR supports processing scopes already
introduced with [personal
tokens](https://docs.gitea.com/development/oauth2-provider#scopes) (e.g.
`read:user`, `write:issue`, `read:group`, `write:repository`...)
Personal tokens define scopes around specific resources: user info,
repositories, issues, packages, organizations, notifications,
miscellaneous, admin, and activitypub, with access delineated by read
and/or write permissions.
The initial case I wanted to address was to have Gitea act as an OAuth2
Identity Provider. To achieve that, with this PR, I would only add
`openid public-only` to provide access token to the third party to
authenticate the Gitea's user but no further access to the API and users
resources.
Another example: if a third party wanted to interact solely with Issues,
it would need to add `read:user` (for authorization) and
`read:issue`/`write:issue` to manage Issues.
My approach is based on my understanding of how scopes can be utilized,
supported by examples like [Sample Use Cases: Scopes and
Claims](https://auth0.com/docs/get-started/apis/scopes/sample-use-cases-scopes-and-claims)
on auth0.com.
I renamed `CheckOAuthAccessToken` to `GetOAuthAccessTokenScopeAndUserID`
so now it returns AccessTokenScope and user's ID. In the case of
additional scopes in `userIDFromToken` the default `all` would be
reduced to whatever was asked via those scopes. The main difference is
the opportunity to reduce the permissions from `all`, as is currently
the case, to what is provided by the additional scopes described above.
Screenshots:


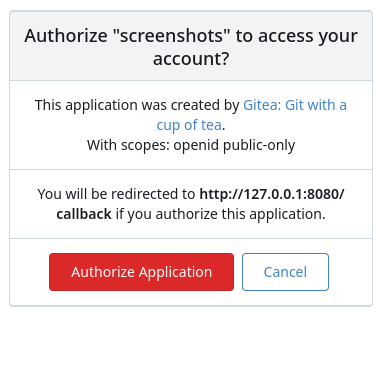

---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
When running e2e tests on flaky networks, gravatar can cause a timeout
and test failures. Turn off, and populate avatars on e2e test suite run
to make them reliable.
- Move models/GetForks to services/FindForks
- Add doer as a parameter of FindForks to check permissions
- Slight performance optimization for get forks API with batch loading
of repository units
- Add tests for forking repository to organizations
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
By some CI fine tunes (`run tests`), SQLite & MSSQL could complete
in about 12~13 minutes (before > 14), MySQL could complete in 18 minutes
(before: about 23 or even > 30)
Major changes:
1. use tmpfs for MySQL storage
1. run `make test-mysql` instead of `make integration-test-coverage`
because the code coverage is not really used at the moment.
1. refactor testlogger to make it more reliable and be able to report
stuck stacktrace
1. do not requeue failed items when a queue is being flushed (failed
items would keep failing and make flush uncompleted)
1. reduce the file sizes for testing
1. use math ChaCha20 random data instead of crypot/rand (for testing
purpose only)
1. no need to `DeleteRepository` in `TestLinguist`
1. other related refactoring to make code easier to maintain
In profiling integration tests, I found a couple places where per-test
overhead could be reduced:
* Avoiding disk IO by synchronizing instead of deleting & copying test
Git repository data. This saves ~100ms per test on my machine
* When flushing queues in `PrintCurrentTest`, invoke `FlushWithContext`
in a parallel.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
There were too many patches to the Render system, it's really difficult
to make further improvements.
This PR clears the legacy problems and fix TODOs.
1. Rename `RenderContext.Type` to `RenderContext.MarkupType` to clarify
its usage.
2. Use `ContentMode` to replace `meta["mode"]` and `IsWiki`, to clarify
the rendering behaviors.
3. Use "wiki" mode instead of "mode=gfm + wiki=true"
4. Merge `renderByType` and `renderByFile`
5. Add more comments
----
The problem of "mode=document": in many cases it is not set, so many
non-comment places use comment's hard line break incorrectly
1. move "internal-lfs" route mock to "common-lfs"
2. fine tune tests
3. fix "realm" strings, according to RFC:
https://datatracker.ietf.org/doc/html/rfc2617:
* realm = "realm" "=" realm-value
* realm-value = quoted-string
4. clarify some names of the middlewares, rename `ignXxx` to `optXxx` to
match `reqXxx`, and rename ambiguous `requireSignIn` to `reqGitSignIn`
Gitea instance keeps reporting a lot of errors like "LFS SSH transfer connection denied, pure SSH protocol is disabled". When starting debugging the problem, there are more problems found. Try to address most of them:
* avoid unnecessary server side error logs (change `fail()` to not log them)
* figure out the broken tests/user2/lfs.git (added comments)
* avoid `migratePushMirrors` failure when a repository doesn't exist (ignore them)
* avoid "Authorization" (internal&lfs) header conflicts, remove the tricky "swapAuth" and use "X-Gitea-Internal-Auth"
* make internal token comparing constant time (it wasn't a serous problem because in a real world it's nearly impossible to timing-attack the token, but good to fix and backport)
* avoid duplicate routers (introduce AddOwnerRepoGitLFSRoutes)
* avoid "internal (private)" routes using session/web context (they should use private context)
* fix incorrect "path" usages (use "filepath")
* fix incorrect mocked route point handling (need to check func nil correctly)
* split some tests from "git general tests" to "git misc tests" (to keep "git_general_test.go" simple)
Still no correct result for Git LFS SSH tests. So the code is kept there
(`tests/integration/git_lfs_ssh_test.go`) and a FIXME explains the details.
From testing, I found that issue posters and users with repository write
access are able to edit attachment names in a way that circumvents the
instance-level file extension restrictions using the edit attachment
APIs. This snapshot adds checks for these endpoints.
Use zero instead of 9999-12-31 for deadline
Fix#32291
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Giteabot <teabot@gitea.io>
1. clarify the "filepath" could(should) contain "{ref}"
2. remove unclear RepoRefLegacy and RepoRefAny, use RepoRefUnknown to guess
3. by the way, avoid using AppURL
Closes https://github.com/go-gitea/gitea/issues/30296
- Adds a DB fixture for actions artifacts
- Adds artifacts test files
- Clears artifacts test files between each run
- Note: I initially initialized the artifacts only for artifacts tests,
but because the files are small it only takes ~8ms, so I changed it to
always run in test setup for simplicity
- Fix some otherwise flaky tests by making them not depend on previous
tests
This introduces a new flag `BlockAdminMergeOverride` on the branch
protection rules that prevents admins/repo owners from bypassing branch
protection rules and merging without approvals or failing status checks.
Fixes#17131
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Giteabot <teabot@gitea.io>
This is a large and complex PR, so let me explain in detail its changes.
First, I had to create new index mappings for Bleve and ElasticSerach as
the current ones do not support search by filename. This requires Gitea
to recreate the code search indexes (I do not know if this is a breaking
change, but I feel it deserves a heads-up).
I've used [this
approach](https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-pathhierarchy-tokenizer.html)
to model the filename index. It allows us to efficiently search for both
the full path and the name of a file. Bleve, however, does not support
this out-of-box, so I had to code a brand new [token
filter](https://blevesearch.com/docs/Token-Filters/) to generate the
search terms.
I also did an overhaul in the `indexer_test.go` file. It now asserts the
order of the expected results (this is important since matches based on
the name of a file are more relevant than those based on its content).
I've added new test scenarios that deal with searching by filename. They
use a new repo included in the Gitea fixture.
The screenshot below depicts how Gitea shows the search results. It
shows results based on content in the same way as the current version
does. In matches based on the filename, the first seven lines of the
file contents are shown (BTW, this is how GitHub does it).

Resolves#32096
---------
Signed-off-by: Bruno Sofiato <bruno.sofiato@gmail.com>
while testing i found out that testing locally as documented in the
changed README.md for pgsql isn't working because of the minio
dependency. reworked this to by default be still docker, but allow for
for local with only minio in docker and testing on bare metal.
also depending on this: fixed docs for running pgsql test
Closes: #32168 (by changing documentation for pgsql tests)
Closes: #32169 (by changing documentation, Makefile & pgsql.ini.tmpl:
adding {{TEST_MINIO_ENDPOINT}})
sry for the combined pr, but when testing I ran into this issue and
first thought they were related and now finally address the same
problem: not beeing able to run pgsql integration tests as described in
the according README.md
Since page templates keep changing, some pages that contained forms with
CSRF token no longer have them.
It leads to some calls of `GetCSRF` returning an empty string, which
fails the tests. Like
3269b04d61/tests/integration/attachment_test.go (L62-L63)
The test did try to get the CSRF token and provided it, but it was
empty.
Multiple chunks are uploaded with type "block" without using
"appendBlock" and eventually out of order for bigger uploads.
8MB seems to be the chunk size
This change parses the blockList uploaded after all blocks to get the
final artifact size and order them correctly before calculating the
sha256 checksum over all blocks
Fixes#31354
This PR addresses the missing `bin` field in Composer metadata, which
currently causes vendor-provided binaries to not be symlinked to
`vendor/bin` during installation.
In the current implementation, running `composer install` does not
publish the binaries, leading to issues where expected binaries are not
available.
By properly declaring the `bin` field, this PR ensures that binaries are
correctly symlinked upon installation, as described in the [Composer
documentation](https://getcomposer.org/doc/articles/vendor-binaries.md).