mirror of
https://github.com/go-gitea/gitea
synced 2024-11-15 06:34:25 +00:00
Many existing tests were quite hacky, these could be improved later. <details> 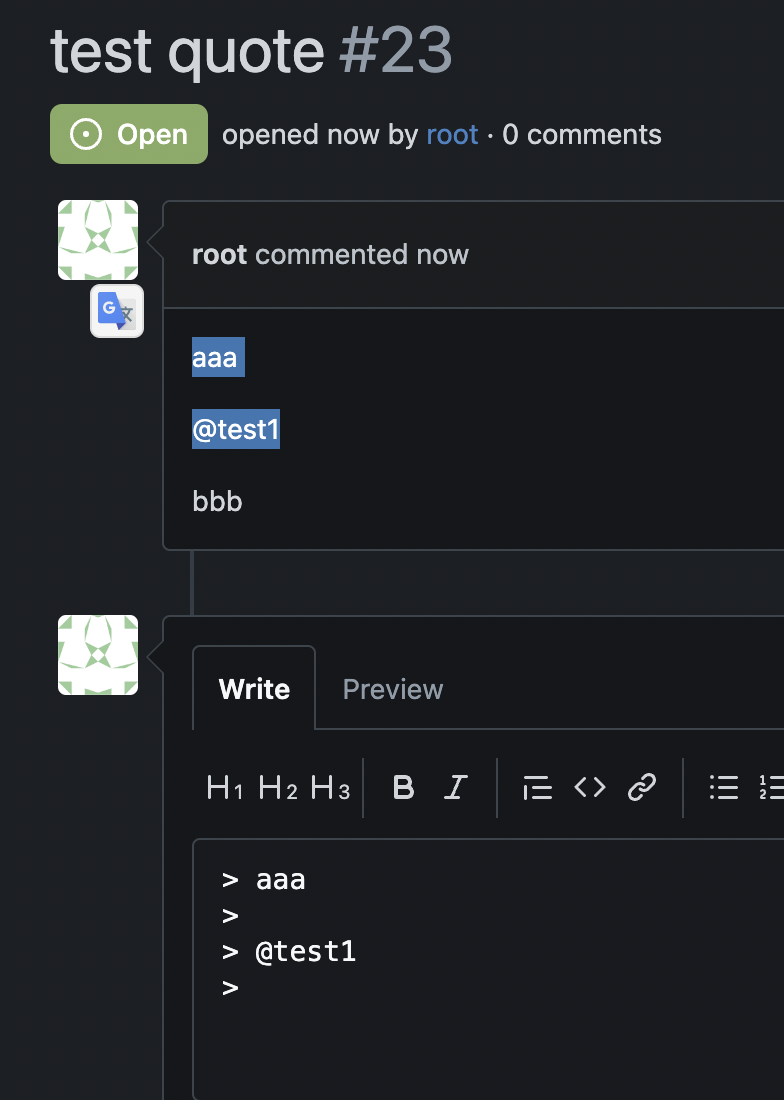 </details>
495 lines
14 KiB
Go
495 lines
14 KiB
Go
// Copyright 2017 The Gitea Authors. All rights reserved.
|
|
// SPDX-License-Identifier: MIT
|
|
|
|
package markup
|
|
|
|
import (
|
|
"bytes"
|
|
"io"
|
|
"regexp"
|
|
"strings"
|
|
"sync"
|
|
|
|
"code.gitea.io/gitea/modules/markup/common"
|
|
"code.gitea.io/gitea/modules/setting"
|
|
|
|
"golang.org/x/net/html"
|
|
"golang.org/x/net/html/atom"
|
|
"mvdan.cc/xurls/v2"
|
|
)
|
|
|
|
// Issue name styles
|
|
const (
|
|
IssueNameStyleNumeric = "numeric"
|
|
IssueNameStyleAlphanumeric = "alphanumeric"
|
|
IssueNameStyleRegexp = "regexp"
|
|
)
|
|
|
|
var (
|
|
// NOTE: All below regex matching do not perform any extra validation.
|
|
// Thus a link is produced even if the linked entity does not exist.
|
|
// While fast, this is also incorrect and lead to false positives.
|
|
// TODO: fix invalid linking issue
|
|
|
|
// valid chars in encoded path and parameter: [-+~_%.a-zA-Z0-9/]
|
|
|
|
// hashCurrentPattern matches string that represents a commit SHA, e.g. d8a994ef243349f321568f9e36d5c3f444b99cae
|
|
// Although SHA1 hashes are 40 chars long, SHA256 are 64, the regex matches the hash from 7 to 64 chars in length
|
|
// so that abbreviated hash links can be used as well. This matches git and GitHub usability.
|
|
hashCurrentPattern = regexp.MustCompile(`(?:\s|^|\(|\[)([0-9a-f]{7,64})(?:\s|$|\)|\]|[.,:](\s|$))`)
|
|
|
|
// shortLinkPattern matches short but difficult to parse [[name|link|arg=test]] syntax
|
|
shortLinkPattern = regexp.MustCompile(`\[\[(.*?)\]\](\w*)`)
|
|
|
|
// anyHashPattern splits url containing SHA into parts
|
|
anyHashPattern = regexp.MustCompile(`https?://(?:\S+/){4,5}([0-9a-f]{40,64})(/[-+~%./\w]+)?(\?[-+~%.\w&=]+)?(#[-+~%.\w]+)?`)
|
|
|
|
// comparePattern matches "http://domain/org/repo/compare/COMMIT1...COMMIT2#hash"
|
|
comparePattern = regexp.MustCompile(`https?://(?:\S+/){4,5}([0-9a-f]{7,64})(\.\.\.?)([0-9a-f]{7,64})?(#[-+~_%.a-zA-Z0-9]+)?`)
|
|
|
|
// fullURLPattern matches full URL like "mailto:...", "https://..." and "ssh+git://..."
|
|
fullURLPattern = regexp.MustCompile(`^[a-z][-+\w]+:`)
|
|
|
|
// emailRegex is definitely not perfect with edge cases,
|
|
// it is still accepted by the CommonMark specification, as well as the HTML5 spec:
|
|
// http://spec.commonmark.org/0.28/#email-address
|
|
// https://html.spec.whatwg.org/multipage/input.html#e-mail-state-(type%3Demail)
|
|
emailRegex = regexp.MustCompile("(?:\\s|^|\\(|\\[)([a-zA-Z0-9.!#$%&'*+\\/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\\.[a-zA-Z0-9]{2,}(?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)+)(?:\\s|$|\\)|\\]|;|,|\\?|!|\\.(\\s|$))")
|
|
|
|
// blackfridayExtRegex is for blackfriday extensions create IDs like fn:user-content-footnote
|
|
blackfridayExtRegex = regexp.MustCompile(`[^:]*:user-content-`)
|
|
|
|
// emojiShortCodeRegex find emoji by alias like :smile:
|
|
emojiShortCodeRegex = regexp.MustCompile(`:[-+\w]+:`)
|
|
)
|
|
|
|
// CSS class for action keywords (e.g. "closes: #1")
|
|
const keywordClass = "issue-keyword"
|
|
|
|
// IsFullURLBytes reports whether link fits valid format.
|
|
func IsFullURLBytes(link []byte) bool {
|
|
return fullURLPattern.Match(link)
|
|
}
|
|
|
|
func IsFullURLString(link string) bool {
|
|
return fullURLPattern.MatchString(link)
|
|
}
|
|
|
|
func IsNonEmptyRelativePath(link string) bool {
|
|
return link != "" && !IsFullURLString(link) && link[0] != '/' && link[0] != '?' && link[0] != '#'
|
|
}
|
|
|
|
// regexp for full links to issues/pulls
|
|
var issueFullPattern *regexp.Regexp
|
|
|
|
// Once for to prevent races
|
|
var issueFullPatternOnce sync.Once
|
|
|
|
// regexp for full links to hash comment in pull request files changed tab
|
|
var filesChangedFullPattern *regexp.Regexp
|
|
|
|
// Once for to prevent races
|
|
var filesChangedFullPatternOnce sync.Once
|
|
|
|
func getIssueFullPattern() *regexp.Regexp {
|
|
issueFullPatternOnce.Do(func() {
|
|
// example: https://domain/org/repo/pulls/27#hash
|
|
issueFullPattern = regexp.MustCompile(regexp.QuoteMeta(setting.AppURL) +
|
|
`[\w_.-]+/[\w_.-]+/(?:issues|pulls)/((?:\w{1,10}-)?[1-9][0-9]*)([\?|#](\S+)?)?\b`)
|
|
})
|
|
return issueFullPattern
|
|
}
|
|
|
|
func getFilesChangedFullPattern() *regexp.Regexp {
|
|
filesChangedFullPatternOnce.Do(func() {
|
|
// example: https://domain/org/repo/pulls/27/files#hash
|
|
filesChangedFullPattern = regexp.MustCompile(regexp.QuoteMeta(setting.AppURL) +
|
|
`[\w_.-]+/[\w_.-]+/pulls/((?:\w{1,10}-)?[1-9][0-9]*)/files([\?|#](\S+)?)?\b`)
|
|
})
|
|
return filesChangedFullPattern
|
|
}
|
|
|
|
// CustomLinkURLSchemes allows for additional schemes to be detected when parsing links within text
|
|
func CustomLinkURLSchemes(schemes []string) {
|
|
schemes = append(schemes, "http", "https")
|
|
withAuth := make([]string, 0, len(schemes))
|
|
validScheme := regexp.MustCompile(`^[a-z]+$`)
|
|
for _, s := range schemes {
|
|
if !validScheme.MatchString(s) {
|
|
continue
|
|
}
|
|
without := false
|
|
for _, sna := range xurls.SchemesNoAuthority {
|
|
if s == sna {
|
|
without = true
|
|
break
|
|
}
|
|
}
|
|
if without {
|
|
s += ":"
|
|
} else {
|
|
s += "://"
|
|
}
|
|
withAuth = append(withAuth, s)
|
|
}
|
|
common.LinkRegex, _ = xurls.StrictMatchingScheme(strings.Join(withAuth, "|"))
|
|
}
|
|
|
|
type postProcessError struct {
|
|
context string
|
|
err error
|
|
}
|
|
|
|
func (p *postProcessError) Error() string {
|
|
return "PostProcess: " + p.context + ", " + p.err.Error()
|
|
}
|
|
|
|
type processor func(ctx *RenderContext, node *html.Node)
|
|
|
|
var defaultProcessors = []processor{
|
|
fullIssuePatternProcessor,
|
|
comparePatternProcessor,
|
|
codePreviewPatternProcessor,
|
|
fullHashPatternProcessor,
|
|
shortLinkProcessor,
|
|
linkProcessor,
|
|
mentionProcessor,
|
|
issueIndexPatternProcessor,
|
|
commitCrossReferencePatternProcessor,
|
|
hashCurrentPatternProcessor,
|
|
emailAddressProcessor,
|
|
emojiProcessor,
|
|
emojiShortCodeProcessor,
|
|
}
|
|
|
|
// PostProcess does the final required transformations to the passed raw HTML
|
|
// data, and ensures its validity. Transformations include: replacing links and
|
|
// emails with HTML links, parsing shortlinks in the format of [[Link]], like
|
|
// MediaWiki, linking issues in the format #ID, and mentions in the format
|
|
// @user, and others.
|
|
func PostProcess(
|
|
ctx *RenderContext,
|
|
input io.Reader,
|
|
output io.Writer,
|
|
) error {
|
|
return postProcess(ctx, defaultProcessors, input, output)
|
|
}
|
|
|
|
var commitMessageProcessors = []processor{
|
|
fullIssuePatternProcessor,
|
|
comparePatternProcessor,
|
|
fullHashPatternProcessor,
|
|
linkProcessor,
|
|
mentionProcessor,
|
|
issueIndexPatternProcessor,
|
|
commitCrossReferencePatternProcessor,
|
|
hashCurrentPatternProcessor,
|
|
emailAddressProcessor,
|
|
emojiProcessor,
|
|
emojiShortCodeProcessor,
|
|
}
|
|
|
|
// RenderCommitMessage will use the same logic as PostProcess, but will disable
|
|
// the shortLinkProcessor and will add a defaultLinkProcessor if defaultLink is
|
|
// set, which changes every text node into a link to the passed default link.
|
|
func RenderCommitMessage(
|
|
ctx *RenderContext,
|
|
content string,
|
|
) (string, error) {
|
|
procs := commitMessageProcessors
|
|
if ctx.DefaultLink != "" {
|
|
// we don't have to fear data races, because being
|
|
// commitMessageProcessors of fixed len and cap, every time we append
|
|
// something to it the slice is realloc+copied, so append always
|
|
// generates the slice ex-novo.
|
|
procs = append(procs, genDefaultLinkProcessor(ctx.DefaultLink))
|
|
}
|
|
return renderProcessString(ctx, procs, content)
|
|
}
|
|
|
|
var commitMessageSubjectProcessors = []processor{
|
|
fullIssuePatternProcessor,
|
|
comparePatternProcessor,
|
|
fullHashPatternProcessor,
|
|
linkProcessor,
|
|
mentionProcessor,
|
|
issueIndexPatternProcessor,
|
|
commitCrossReferencePatternProcessor,
|
|
hashCurrentPatternProcessor,
|
|
emojiShortCodeProcessor,
|
|
emojiProcessor,
|
|
}
|
|
|
|
var emojiProcessors = []processor{
|
|
emojiShortCodeProcessor,
|
|
emojiProcessor,
|
|
}
|
|
|
|
// RenderCommitMessageSubject will use the same logic as PostProcess and
|
|
// RenderCommitMessage, but will disable the shortLinkProcessor and
|
|
// emailAddressProcessor, will add a defaultLinkProcessor if defaultLink is set,
|
|
// which changes every text node into a link to the passed default link.
|
|
func RenderCommitMessageSubject(
|
|
ctx *RenderContext,
|
|
content string,
|
|
) (string, error) {
|
|
procs := commitMessageSubjectProcessors
|
|
if ctx.DefaultLink != "" {
|
|
// we don't have to fear data races, because being
|
|
// commitMessageSubjectProcessors of fixed len and cap, every time we
|
|
// append something to it the slice is realloc+copied, so append always
|
|
// generates the slice ex-novo.
|
|
procs = append(procs, genDefaultLinkProcessor(ctx.DefaultLink))
|
|
}
|
|
return renderProcessString(ctx, procs, content)
|
|
}
|
|
|
|
// RenderIssueTitle to process title on individual issue/pull page
|
|
func RenderIssueTitle(
|
|
ctx *RenderContext,
|
|
title string,
|
|
) (string, error) {
|
|
return renderProcessString(ctx, []processor{
|
|
issueIndexPatternProcessor,
|
|
commitCrossReferencePatternProcessor,
|
|
hashCurrentPatternProcessor,
|
|
emojiShortCodeProcessor,
|
|
emojiProcessor,
|
|
}, title)
|
|
}
|
|
|
|
func renderProcessString(ctx *RenderContext, procs []processor, content string) (string, error) {
|
|
var buf strings.Builder
|
|
if err := postProcess(ctx, procs, strings.NewReader(content), &buf); err != nil {
|
|
return "", err
|
|
}
|
|
return buf.String(), nil
|
|
}
|
|
|
|
// RenderDescriptionHTML will use similar logic as PostProcess, but will
|
|
// use a single special linkProcessor.
|
|
func RenderDescriptionHTML(
|
|
ctx *RenderContext,
|
|
content string,
|
|
) (string, error) {
|
|
return renderProcessString(ctx, []processor{
|
|
descriptionLinkProcessor,
|
|
emojiShortCodeProcessor,
|
|
emojiProcessor,
|
|
}, content)
|
|
}
|
|
|
|
// RenderEmoji for when we want to just process emoji and shortcodes
|
|
// in various places it isn't already run through the normal markdown processor
|
|
func RenderEmoji(
|
|
ctx *RenderContext,
|
|
content string,
|
|
) (string, error) {
|
|
return renderProcessString(ctx, emojiProcessors, content)
|
|
}
|
|
|
|
var (
|
|
tagCleaner = regexp.MustCompile(`<((?:/?\w+/\w+)|(?:/[\w ]+/)|(/?[hH][tT][mM][lL]\b)|(/?[hH][eE][aA][dD]\b))`)
|
|
nulCleaner = strings.NewReplacer("\000", "")
|
|
)
|
|
|
|
func postProcess(ctx *RenderContext, procs []processor, input io.Reader, output io.Writer) error {
|
|
defer ctx.Cancel()
|
|
// FIXME: don't read all content to memory
|
|
rawHTML, err := io.ReadAll(input)
|
|
if err != nil {
|
|
return err
|
|
}
|
|
|
|
// parse the HTML
|
|
node, err := html.Parse(io.MultiReader(
|
|
// prepend "<html><body>"
|
|
strings.NewReader("<html><body>"),
|
|
// Strip out nuls - they're always invalid
|
|
bytes.NewReader(tagCleaner.ReplaceAll([]byte(nulCleaner.Replace(string(rawHTML))), []byte("<$1"))),
|
|
// close the tags
|
|
strings.NewReader("</body></html>"),
|
|
))
|
|
if err != nil {
|
|
return &postProcessError{"invalid HTML", err}
|
|
}
|
|
|
|
if node.Type == html.DocumentNode {
|
|
node = node.FirstChild
|
|
}
|
|
|
|
visitNode(ctx, procs, node)
|
|
|
|
newNodes := make([]*html.Node, 0, 5)
|
|
|
|
if node.Data == "html" {
|
|
node = node.FirstChild
|
|
for node != nil && node.Data != "body" {
|
|
node = node.NextSibling
|
|
}
|
|
}
|
|
if node != nil {
|
|
if node.Data == "body" {
|
|
child := node.FirstChild
|
|
for child != nil {
|
|
newNodes = append(newNodes, child)
|
|
child = child.NextSibling
|
|
}
|
|
} else {
|
|
newNodes = append(newNodes, node)
|
|
}
|
|
}
|
|
|
|
// Render everything to buf.
|
|
for _, node := range newNodes {
|
|
if err := html.Render(output, node); err != nil {
|
|
return &postProcessError{"error rendering processed HTML", err}
|
|
}
|
|
}
|
|
return nil
|
|
}
|
|
|
|
func visitNode(ctx *RenderContext, procs []processor, node *html.Node) *html.Node {
|
|
// Add user-content- to IDs and "#" links if they don't already have them
|
|
for idx, attr := range node.Attr {
|
|
val := strings.TrimPrefix(attr.Val, "#")
|
|
notHasPrefix := !(strings.HasPrefix(val, "user-content-") || blackfridayExtRegex.MatchString(val))
|
|
|
|
if attr.Key == "id" && notHasPrefix {
|
|
node.Attr[idx].Val = "user-content-" + attr.Val
|
|
}
|
|
|
|
if attr.Key == "href" && strings.HasPrefix(attr.Val, "#") && notHasPrefix {
|
|
node.Attr[idx].Val = "#user-content-" + val
|
|
}
|
|
|
|
if attr.Key == "class" && attr.Val == "emoji" {
|
|
procs = nil
|
|
}
|
|
}
|
|
|
|
switch node.Type {
|
|
case html.TextNode:
|
|
processTextNodes(ctx, procs, node)
|
|
case html.ElementNode:
|
|
if node.Data == "code" || node.Data == "pre" {
|
|
// ignore code and pre nodes
|
|
return node.NextSibling
|
|
} else if node.Data == "img" {
|
|
return visitNodeImg(ctx, node)
|
|
} else if node.Data == "video" {
|
|
return visitNodeVideo(ctx, node)
|
|
} else if node.Data == "a" {
|
|
// Restrict text in links to emojis
|
|
procs = emojiProcessors
|
|
} else if node.Data == "i" {
|
|
for _, attr := range node.Attr {
|
|
if attr.Key != "class" {
|
|
continue
|
|
}
|
|
classes := strings.Split(attr.Val, " ")
|
|
for i, class := range classes {
|
|
if class == "icon" {
|
|
classes[0], classes[i] = classes[i], classes[0]
|
|
attr.Val = strings.Join(classes, " ")
|
|
|
|
// Remove all children of icons
|
|
child := node.FirstChild
|
|
for child != nil {
|
|
node.RemoveChild(child)
|
|
child = node.FirstChild
|
|
}
|
|
break
|
|
}
|
|
}
|
|
}
|
|
}
|
|
for n := node.FirstChild; n != nil; {
|
|
n = visitNode(ctx, procs, n)
|
|
}
|
|
default:
|
|
}
|
|
return node.NextSibling
|
|
}
|
|
|
|
// processTextNodes runs the passed node through various processors, in order to handle
|
|
// all kinds of special links handled by the post-processing.
|
|
func processTextNodes(ctx *RenderContext, procs []processor, node *html.Node) {
|
|
for _, p := range procs {
|
|
p(ctx, node)
|
|
}
|
|
}
|
|
|
|
// createKeyword() renders a highlighted version of an action keyword
|
|
func createKeyword(content string) *html.Node {
|
|
span := &html.Node{
|
|
Type: html.ElementNode,
|
|
Data: atom.Span.String(),
|
|
Attr: []html.Attribute{},
|
|
}
|
|
span.Attr = append(span.Attr, html.Attribute{Key: "class", Val: keywordClass})
|
|
|
|
text := &html.Node{
|
|
Type: html.TextNode,
|
|
Data: content,
|
|
}
|
|
span.AppendChild(text)
|
|
|
|
return span
|
|
}
|
|
|
|
func createLink(href, content, class string) *html.Node {
|
|
a := &html.Node{
|
|
Type: html.ElementNode,
|
|
Data: atom.A.String(),
|
|
Attr: []html.Attribute{
|
|
{Key: "href", Val: href},
|
|
{Key: "data-markdown-generated-content"},
|
|
},
|
|
}
|
|
|
|
if class != "" {
|
|
a.Attr = append(a.Attr, html.Attribute{Key: "class", Val: class})
|
|
}
|
|
|
|
text := &html.Node{
|
|
Type: html.TextNode,
|
|
Data: content,
|
|
}
|
|
|
|
a.AppendChild(text)
|
|
return a
|
|
}
|
|
|
|
// replaceContent takes text node, and in its content it replaces a section of
|
|
// it with the specified newNode.
|
|
func replaceContent(node *html.Node, i, j int, newNode *html.Node) {
|
|
replaceContentList(node, i, j, []*html.Node{newNode})
|
|
}
|
|
|
|
// replaceContentList takes text node, and in its content it replaces a section of
|
|
// it with the specified newNodes. An example to visualize how this can work can
|
|
// be found here: https://play.golang.org/p/5zP8NnHZ03s
|
|
func replaceContentList(node *html.Node, i, j int, newNodes []*html.Node) {
|
|
// get the data before and after the match
|
|
before := node.Data[:i]
|
|
after := node.Data[j:]
|
|
|
|
// Replace in the current node the text, so that it is only what it is
|
|
// supposed to have.
|
|
node.Data = before
|
|
|
|
// Get the current next sibling, before which we place the replaced data,
|
|
// and after that we place the new text node.
|
|
nextSibling := node.NextSibling
|
|
for _, n := range newNodes {
|
|
node.Parent.InsertBefore(n, nextSibling)
|
|
}
|
|
if after != "" {
|
|
node.Parent.InsertBefore(&html.Node{
|
|
Type: html.TextNode,
|
|
Data: after,
|
|
}, nextSibling)
|
|
}
|
|
}
|